SQL技巧:行列转换
目录
excel 有一个功能叫数据透视表。它可以把一表格中的一列数据,作为列字段横向或者行字段竖向展开,将原来一个一维表扩展至二维表格。最经典的例子就是产品区域销售量数据表。
数据透视表 #

把左边地区产品销售量明细,按 产品-区域 或 区域-产品 的方式进行透视。透视图只需要定义二维表格的列字段、行字段、值字段计算方式即可。
😳 excel 中并没有透视表功能相反的 数据表反透视。要将上面例子中的二维表格转换为一维的明细数据表格,要么编写VBA宏函数,要么使用 excel 2016版以后才带的 power query 定义 table transform,95%的用户基本都被难住了,只能希望老板不要有这样数据操作要求。
仔细研究一下,使用数据透视表来透视数据时,被改变的部分往往是可以看作维度的列。
表格数据转置 #
表格转置,把行变成列、列转换成行。被转置的整个表格,所有数据没有丢失或者增加,原来的列(行)数与列(行)顺序,变成了行(列)数与行(列)顺序。简单讲,就是原来表格要横(竖)着看,转置后要反过来。

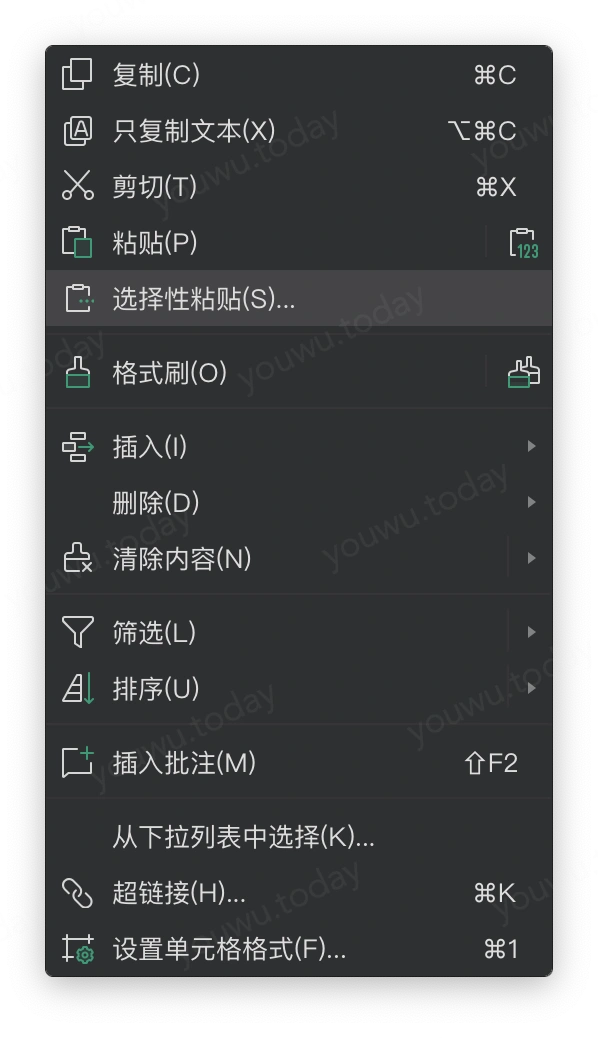
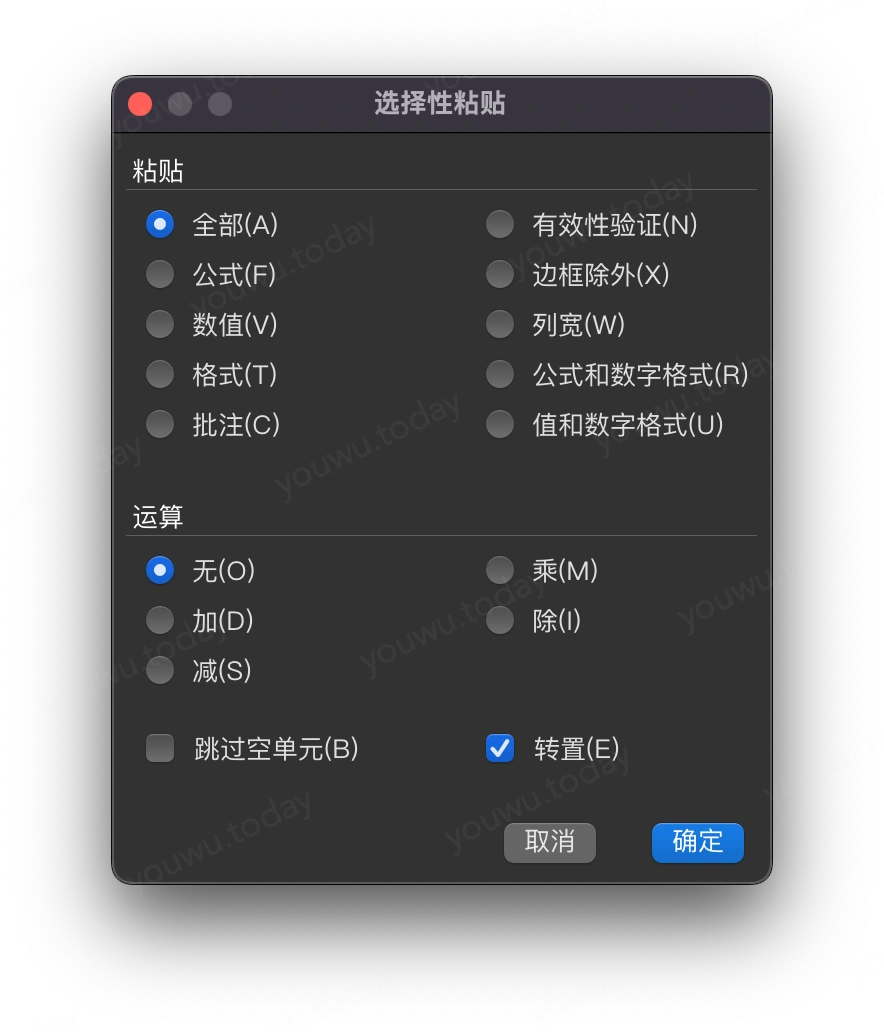
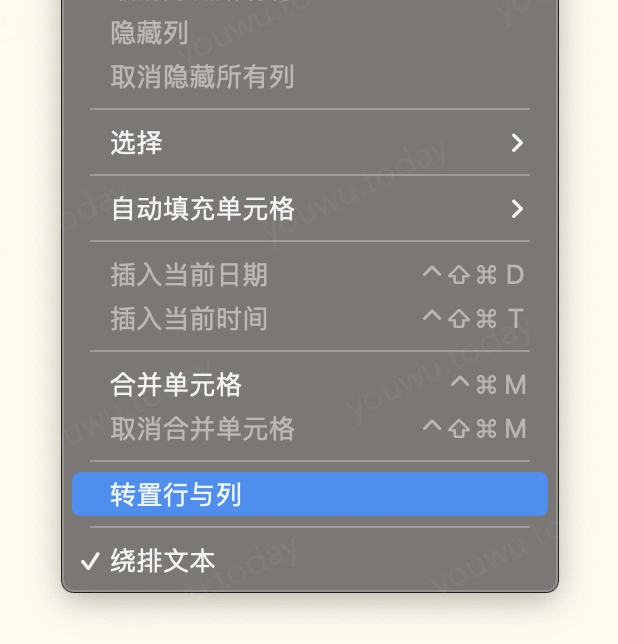
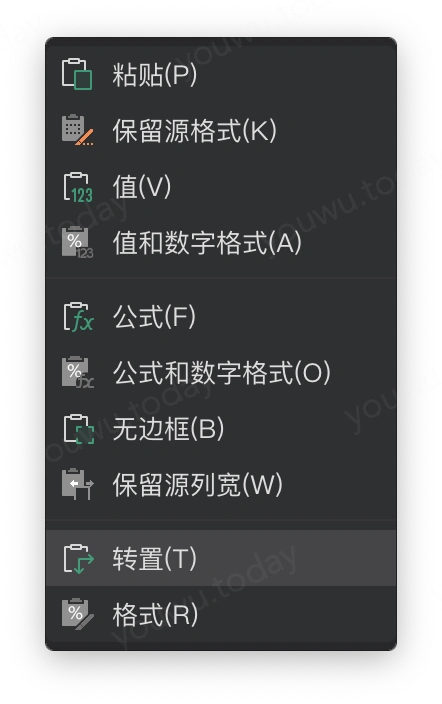
微软的 excel、apple家的 numbers、金山的wps表格,都有转置的功能,只是分布在不同的地方。
比如 excel与wps表格,采用复制表格的方式,在粘贴时选择 选择性粘贴 来转置表格。而 numbers 则是选择目标表格(这个表格不能被数据透视化),再通过 菜单栏 → 表格 → 转行与列 菜单来转置。
sql 实现数据行列转置 #
⚠️ 在谈 sql 实现行列转换 之前,为什么会先谈表格转置呢?
通过上面的例子,我们已经知道什么是表格转置。但在谈 sql 实现行列转换 之前,还是需要搞清楚一些概念与概念。
在上面的表格转置示例中,有这些明显或隐藏的概念:
- 表格有标题行
- 用来做列标题的行;若用于表示数据列之间的维度,可以有多行。只是平时习惯于只使用第一行来做数据列的标题,把维度做为标题列。
- 表格有标题列
- 用来标识每行数据的维度,可以多维度多列。
- 表格转置
- 只涉及位置交换,不重新进行数据计算
- 数据透视
- 可根据需要设置透视表的列、行维度,并定义交叉部分的数值计算公式。再次重申,被透视的,是改变
维度方向来得到一张新数据表格,维度行中的值变成标题,不再是数据。
在关系型数据库,列标题(字段名)是固定的,是元数据,不是数据。其它维度、事实等是实际需要数据库开辟与其数据类型对应的列数据。通常数据表的设计,会将维度作为列与事实数据保存在一起。数据的增加以行的方式追加到表中。这个结构是根据数据定义事先精心设计的。
- 列标题(column name , field name)
- 用于标识数据列、说明作用、横向的数据行。没看错,它就是标题行(headline)。
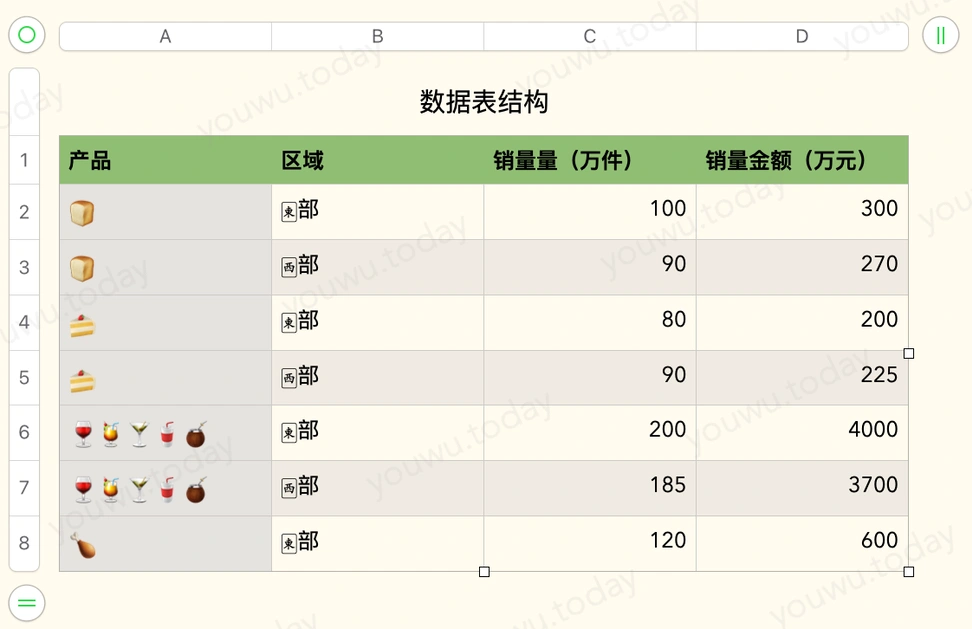
一般地,按照数据库表的设计范式,维度类似于表格工具中的标题列按行保存。由于统计或者报表展示的需要,经常需要将维度值以列的方式横向展开,这时就会出现类似于数据表格工具中的 数据透视表。在现有表的基础上,选择具体的某个或多个维度,横向展示。如文章开头的透视表,将竖向(标题列)的 区域 维度转为横向的列标题(标题行)。
⚠️ 在描述转置的过程中,有悟有意将竖向、横向、列标题、标题行、行标题、标题列等概念混淆在一起。这里没有统一叫法,只是不同领域有不同的习惯用语。在数据开发领域,会把 列标题 称为 列名,标题列 称为 维度。这些概念需要读者你自己悟懂,取舍选择;有时也只是为了听懂别人的用语。(中文实在太强大,列 字在标题之前是定语,在标题之后是主语)
迷惑的术语
| 术语 | 解释 |
|---|---|
| headline | 横向的标题,即 列标题,也叫 标题行,比较常见。 |
| dimension | 竖向的标题,即 行标题,也叫 标题列。习惯称它为 维度。 |
| 行转列 | 在表格工具,把 维度值 横向展开。数据开发领域,还把它称为 长表 → 宽表 |
| 列转行 | 收缩横向相同维度属性的值,并编码归类做为事实数据的维度标识。这时数据表会归约为 维度列+数据列 形式,行数变多。数据开发领域称它为 宽表 → 长表 |
| 表格转置 | 数据按表格的左上角、右下角为对称线进行旋转,互换位置(如果你学习过矩阵,应该非常清楚,这是矩阵转置) |
⚠️ 看到这里,是不是想嘁 “老爸,我大二的线性代数没学好!”
能忍着有悟的啰嗦,看到此处(SQL实现行列转换还没正式登场),实属不易。尚若你对上面所述内容还不太熟悉,建议多看几遍后再继续往下。
有悟写用户操作类的手册一般会用很多“然后”、“再”、“接着”,相当之啰嗦,就怕漏掉一个步骤让读者连贯不起来。而对SQL,一般更想分享抽象通用的方法,要掌握其中的要点,需要对细节概念有清楚的认识,不能单纯地照🐯画🙀。
进入主题。

行转列 - 通用方法 #
将某维度列转置,列数变多,行数变少。
select 维度1
, sum(case when 维度2= '值1' then 事实1 end) as 值1_事实1
, sum(case when 维度2= '值2' then 事实1 end) as 值2_事实1
, sum(case when 维度2= ... then 事实1 end) as ..._事实1
from 数据表
group by 维度1 [,维度2,...]
- 核心要点:
将维度数据变为列的属性 - 特征:列数变多,行数变少
上面小目标使用通用方法写为:
# 以 oracle 为例
with 小目标 as (
select '赚多少钱' item, '一个亿' val from dual union all
select '多长时间' item, '十年' val from dual
)
-- 因为 val 不是数字型,故使用 max。
select max(case when item = '赚多少钱' then val end ) 赚多少钱
, max(case when item = '多长时间' then val end ) 多长时间
from 小目标
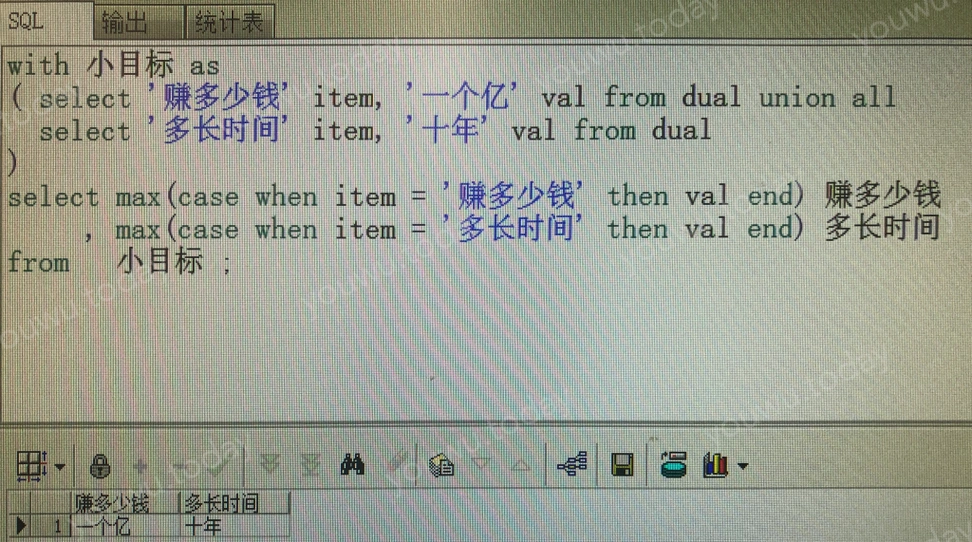
维度列(item)从数据转为列标题,它被从数据中抹去,仅为查询的列标题。
⚠️ 重要的事说第三遍,维度从item列的值变成了列标题,成为查询视图定义的一部分,是元数据,不再是表中数据。
列转行 - 通用方法 #
将多列数据归并是维度,列数变少,行数变多 在类似于excel的表格工具中,没有与数据透视表相反的反透视功能。
select '维度值1' as 维度1, 值1_事实1 as 事实1 from 数据表
union all
select '维度值2' as 维度1, 值2_事实1 as 事实1 from 数据表
- 核心要领:
抽象事实数据列的属性,构造维度 - 特征:列数变少,行数变多
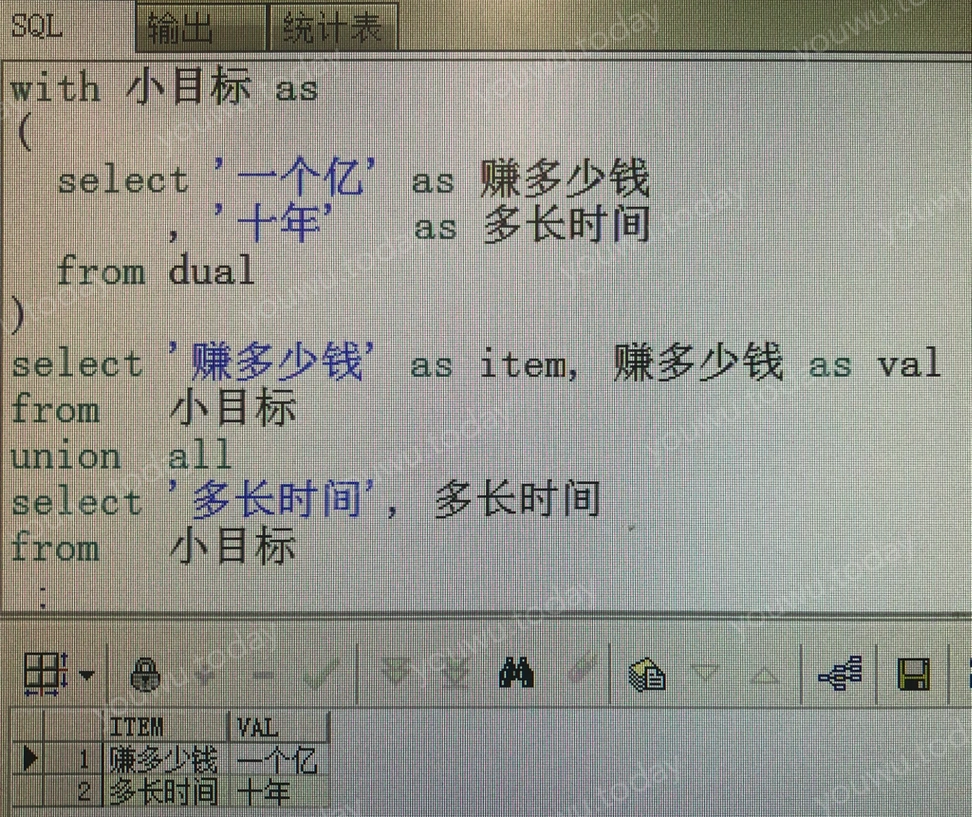
以小目标为例,列转行通用写法为:
with 小目标 as (
select '一个亿' as 赚多少钱
, '十年' as 多长时间
from dual
)
select '赚多长钱' as item, 赚多少钱 as val
from 小目标
union all
select '多长时间' as item, 多长时间
from 小目标
构建维度列(item),对应不同的事实数据,使用 union all 将各个结果拼接起来,确保数据行数完整。
维度列的值原先并不存在,是人为附加上的
至此,行转列、列转行 已经讲完。(有偿搞错,弄半天,就一个 group by,一个 union all。)行列转换的需求较常出现,一些商业数据库产品还是内置了实现。有兴趣的可以看下文。
以下是 升level装x显摆的部分。
行转列(pivot rows)- oracle 专有语法 #
-- oracle
with 小目标 as (
select '赚多少钱' item, '一个亿' val from dual union all
select '多长时间' item, '十年' val from dual
)
select *
from 小目标
pivot (
-- 一个汇总函数,因 val 并非数字类型,故用max
max(val)
for item
-- 类似于excel中数据透视表的列定义
in ('赚多少钱', '多长时间')
)
| 赚多少钱 | 多长时间 |
|---|---|
| 一个亿 | 十年 |
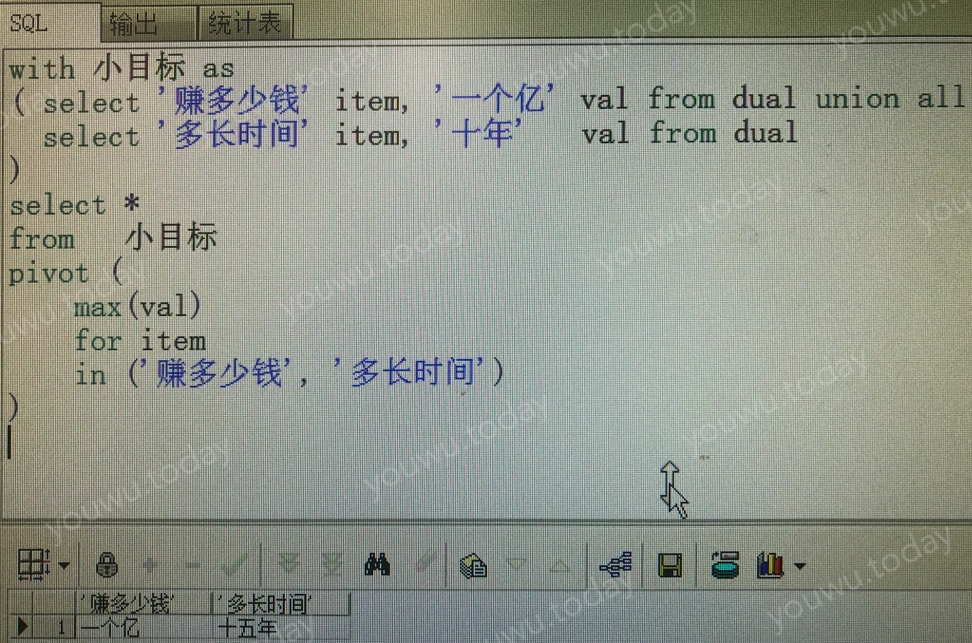
行转列 - hivesql 语法 #
-- hivesql
with 小目标 as (
select '赚多少钱' item, '一个亿' val from system.dual union all
select '多长时间' item, '十年' val from system.dual
)
, mapped as (
select map(item, val) kv
from 小目标
)
select max(kv['赚多少钱'])
, max(kv['多长时间'])
from mapped
hivesql有类似于 java map<T,T> 的数据类型(底层是java实现的,保留java 数据类型来增强hivesql的功能不是坏事),它可以将多个列包装成 key-value 组合。如果不清楚什么是 java map 类型,可以把它看成 json,或者python 的 dict。
本例其实与通用SQL的实现相同,借助了 map(item, val)、mapped_column['key_name'],让查询语句看起来比较另类,仔细观察,它与 case when ... then ... end 或者 decode() 的实现思路是相同的。
-- map 的用法
map(key1, value1, key2, value2 [, ...])
使用 map 中的 key 来选择 value: mapped[key]。
列转行(unpivot) - oracle 专有语法 #
-- oracle
with 小目标 as (
select '一个亿' as 赚多少钱
, '十年' as 多长时间
from dual
)
select *
from 小目标
unpivot
( "多少" for "数据项" in (赚多少钱, 多长时间));
| 数据项 | 多少 |
|---|---|
| 赚多少钱 | 一个亿 |
| 多长时间 | 十年 |
列转行 - hivesql 专有语法 #
-- oracle
with 小目标 as (
select '一个亿' as 赚多少钱
, '十年' as 多长时间
from system.dual
)
, mapped as (
select map(
'赚多少钱', 赚多少钱
'多长时间', 多长时间
) kv
from 小目标
)
select e.*
from mapped
lateral view explode(kv) as e;
将最后的 lateral view ... 去掉,把查询改为 select * from mapped,结果与上一小节没什么两样,都是一个 map 类型的数据。起作用的是 explode() 函数,它接收集合类参数,如列表、集合、map等。 latreal view 这个写法比较奇怪,它是 hivesql 特有的语法(只能死记)。lateral view explode(kv) 的意思是,根据所紧接着的查询 mapped 创建新的虚拟视图,explode 将 kv 列按 key值 展开为多行,explode(map类型) as e 默认使用 key 来读键列,value 来读值列,或 explode(map类型) e as k, v来指定键列、值列的列别名。
上面SQL的最后一个查询,还可以写成
with ...
select explode(kv)
from mapped
不过,有时结果集除 key、value列之外,可能还需要其它列,这时就需要繁琐一些,用完整语法,并且把结果包装成一个查询。
with ...
, exploded as (
-- 包装成一个子查询,并明确所有外部可见的列
select t.某某列,..., e.key, e.value
from mapped t
lateral view explode(kv) e
)
select ...
from exploded