在 SQL 中拼接字符串
目录
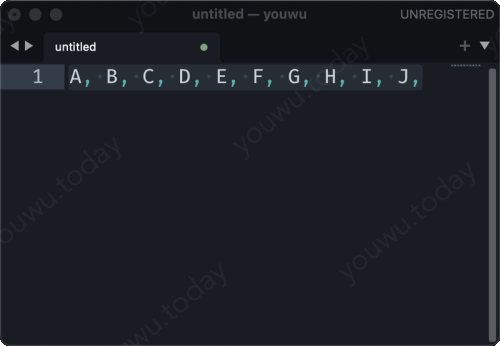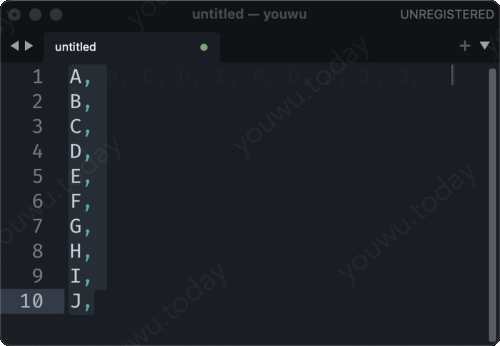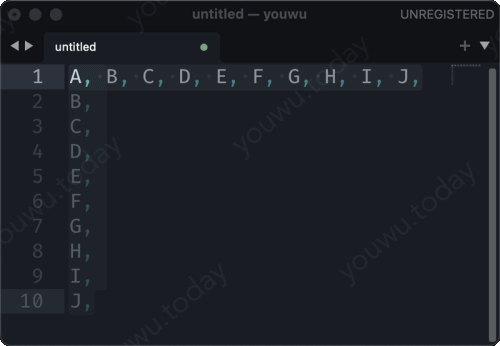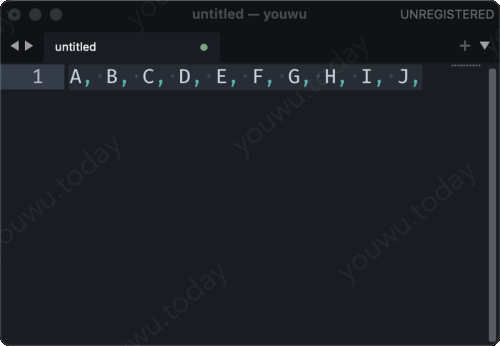
把多行字符串,使用逗号连接起来。有人说,“我会,java 里有 string.join() 方法,可以把字符串数据拼接起来”。也有人会说,“我在 sublime text 里面使用 ctrl+j 就可以把多行拼接起来”。那如果是在SQL里呢,有秘诀吗?
当然,如果是刚接触数据库不久,使用的数据库版本一般较新,会说,“我知道,oracle 有 listsagg 函数,mysql 数据库也有功能一样的函数”。
没错,listagg 是 ISO:2016 标准中的新函数,
What’s New in SQL:2016 #listagg
中给出了详细的说明。
LISTAGG,非常好记,aggrete a (string) list,聚合一个字符串列表。本文不是为比较各数据库实现字符串分组拼接的差异,而是演示各数据库中相似的功能。通用的字符串分组拼接可以实现,缺少内置支持也可以构造出来,以此拓宽思路。
一众分组聚合字符串连接函数 #
除 oracle 11g2 采用 listagg 外,其它数据库的有自己的版本。
| 函数名 | 数据库及支持的版本 |
|---|---|
| listagg | oracle 11g2+ |
| string_agg | postgres 9.0+ |
| group_concat | mysql 5.6 + |
| group_concat | sqlite 3 |
oracle 中的 LISTAGG #
LISTAGG 函数的语法比较别扭,加了一个尾巴 within group(order by ...)用于指定拼接时各字符串的顺序。
LISTAGG(<expr>, <separator>) WITHIN GROUP(ORDER BY …)
postgres 中的 STRING_AGG #
STRING_AGG ( expression, separator [order_by_clause] )
order_by_clause: ORDER BY expression1 {ASC | DESC}, [...]
而 postgres,使用的是 STRING_AGG 函数,非常个性,就是不用 listagg,直接告诉用户,本函数就是用来做“字符串 agg”的。函数也没尾巴,不过要小心,排序的 order by 子句在分隔符 separator 之后,两者之间并无逗号(“,”)。
- 简单示例
psql (14.2)
Type "help" for help.
postgres=# select generate_series(1,3,1);
generate_series
-----------------
1
2
3
(3 rows)
generate_series 是 postgres 中用于生成序列的表函数(返回值类型为结果集的函数)。
select string_agg(cast(seq as varchar(1)), ',')
, string_agg(cast(seq as varchar(1)), ',' order by seq desc)
from generate_series(1,3,1) as seq;
string_agg 只接受字符类型的参数, postgres 此处没有隐式转换类型,故使用 cast 将拼接的数字强制类型转换为 varchar 类型,使用 order by 可指定连接中的元素顺序。结果为:
string_agg | string_agg
------------+------------
1,2,3 | 3,2,1
(1 row)
mysql 中的 GROUP_CONCAT #
msyql 使用的是 group_concat 函数,也没有 within group 尾巴。该函数的用法,参数的第一部分由要的拼接的字段组成。缺省排序与分隔符(默认为逗号)。
-- mysql 语法
GROUP_CONCAT([DISTINCT] expr [,expr ...]
[ORDER BY {unsigned_integer | col_name | expr}
[ASC | DESC] [,col_name ...]]
[SEPARATOR str_val])
- 简要示例
mysql> select * from (values row(1), row(a), row(2)) as t(seq);
+-----+
| seq |
+-----+
| 1 |
| a |
| 2 |
+-----+
3 rows in set (0.00 sec)
values row(1) 的用法,
在 mysql 8.0.19 版本引入
。若数据库版本较低的,可以使用 union all 拼数据集。
select group_concat(seq order by seq desc)
, group_concat(seq order by seq)
from (values row(1), row('a'), row(2)) as t(seq) ;
GROUP_CONCAT 函数默认不排序,使用 order by 来影响字符串顺序。结果为:
+-------------------------------------+--------------------------------+
| group_concat(seq order by seq desc) | group_concat(seq order by seq) |
+-------------------------------------+--------------------------------+
| a,2,1 | 1,2,a |
+-------------------------------------+--------------------------------+
使用 distinct 关键字,可去除排列重复元素。
select group_concat(distinct seq)
, group_concat(seq)
from (values row(1), row('a'), row(2), row(4), row('a'), row(2)) as t(seq);
结果为:
+----------------------------+-------------------+
| group_concat(distinct seq) | group_concat(seq) |
+----------------------------+-------------------+
| 1,2,3,4 | 1,3,2,4,3,2 |
+----------------------------+-------------------+
sqlite3 中的 GROUP_CONCAT #
- 简单示例
SQLite version 3.37.0 2021-12-09 01:34:53
Enter ".help" for usage hints.
sqlite> .mode markdown
sqlite> select *
...> from (values (1),('b'),(3),(4),('a'));
| column1 |
|---------|
| 1 |
| b |
| 3 |
| 4 |
| a |
使用 values 关键字构建一个多行的数据集。
select group_concat(column1)
, group_concat(distinct column1)
from (values (1),('b'),(3),(4),('a'),('b'), (1)) ;
函数 group_concat 的用法与 mysql 中的类似。结果为:
| group_concat(column1) | group_concat(distinct column1) |
|-----------------------|--------------------------------|
| 1,b,3,4,a,b,1 | 1,b,3,4,a |
不过,sqlite3 的 group_concat 没有排序功能的 order by 子语,为了得到顺序或者倒序的结果,需要使用子查询先进行排序。
select ( select group_concat(distinct seq)
from ( select column1 as seq
from (values (1),('b'),(4),('a'),('b'),(1)) order by 1 ))
as concat_1
, ( select group_concat(distinct seq)
from ( select column1 as seq
from (values (1),('b'),(3),('a'),('b'),(1)) order by 1 desc))
as concat_2 ;
结果为:
| concat_1 | concat_2 |
|----------|----------|
| 1,4,a,b | b,a,3,1 |
没有内置分组聚合函数的时代 #
本小节内容才是本文的 重点❗️。
早在有悟开始玩SQL的时候,数据库产品的内置函数已经相当丰富,但像字符串拼接函数(2016年才加入SQL标准)这种使用场景较少的,还是缺了。
使用递归查询的方式 #
字符串列表的拼接,其实是对每一行数据(字符类型)进行累积计算(拼接),SQL逐行累积计算,正好可用递归循环的实现。有悟专门介绍过 《递归查询》 ,让我们试试看使用 recursive 查询能否做到?
将四行数据变成两行:
title name title names
----- ----- -> ----- -----
a youwu a today.youwu
a today b 今日.有悟
b 今日
b 有悟
-- coded in sqlite3
with recursive
seq(title, name) as
( values ('a', 'youwu'), ('a', 'today') , ('b', '今日'), ('b', '有悟') )
, seq_ordered(title, name, row_no) as
( select title, name, ROW_NUMBER() OVER( partition by title order by name)
from seq
)
, lop(title, names, row_no) as
( select title, name, row_no
from seq_ordered
where row_no = 1
union all
select lop.title, lop.names || '.' || seq.name, seq.row_no
from lop, seq_ordered seq
where lop.title = seq.title
and lop.row_no + 1 = seq.row_no
)
, selected(title, names, select_no1) as
( select title, names, ROW_NUMBER() over(partition by title order by row_no desc)
from lop
)
select title, names
from selected
where select_no1 = 1
结果为:
| title | names |
|-------|-------------|
| a | today.youwu |
| b | 今日.有悟 |
how is it possible? 🤔
首先,构建数据集,
with
seq(title, name) as
( values ('a', 'youwu'), ('a', 'today') , ('b', '今日'), ('b', '有悟') )
select *
from seq ;
得到
title name
----- -----
a youwu
a today
b 今日
b 有悟
为了使用递归查询来拼接数据,需要先为每行数据编号(排序)。
with
seq(title, name) as
( values ('a', 'youwu'), ('a', 'today') , ('b', '今日'), ('b', '有悟') )
, seq_ordered(title, name, row_no) as
( select title, name, ROW_NUMBER() OVER( partition by title order by name)
from seq
)
select *
from seq_ordered
可以得到:
title name row_no
----- ----- ------
a today 1
a youwu 2
b 今日 1
b 有悟 2
这样就可以使用递归循环了(有初始条件,row_no = 1)。试试看递归循环的逻辑会产生什么结果,
with recursive
seq(title, name) as
( values ('a', 'youwu'), ('a', 'today') , ('b', '今日'), ('b', '有悟') )
, seq_ordered(title, name, row_no) as
( select title, name, ROW_NUMBER() OVER( partition by title order by name)
from seq
)
, lop(title, names, row_no) as
( select title, name, row_no
from seq_ordered
where row_no = 1
union all
select lop.title, lop.names || '.' || seq.name, seq.row_no
from lop, seq_ordered seq
where lop.title = seq.title
and lop.row_no + 1 = seq.row_no
)
select *
from lop ;
记得加上 recursive 关键字(虽然sqlite中不强制)。使用 seq_ordered 子查询 row_no = 1 做为起始行,按 “row_no 增加 1” 的方式循环从 seq_ordered 中找出数据,并把 name 连到一起。在 recurive-query 部分,使用了条件 lop.title = seq.title,因此字符串连接仅在相同的 title 值间进行,结果为:
title names row_no
----- ----------- ------
a today 1
b 今日 1
a today.youwu 2
b 今日.有悟 2
似乎还久点什么 🧐。需要从这个结果中挑出目标行。从条件 lop.row_no + 1 = seq.row_no 看,循环按 row_no 逐次递增,意味着目标行的 row_no 在 title 分组内值最大,故而:
...
, selected(title, names, select_no1) as
( select title, names, ROW_NUMBER() over(partition by title order by row_no desc)
from lop
)
...
使用 row_number() over() 分析函数对上一步结果按 row_no 的值按降序排列。只要查询 selected 子查询,并筛选 select_no1 = 1 即可得到目标数据行。
本例在 sqlite3 环境中完成。
🧐 作业: 在 postgres、mysql、oracle 中使用相同的递归查询实现 ?看能不能一次性准确的写出来。
使用自定义函数 #
字符串拼接带有分组聚合的特征,如果要自定义函数,意味着函数:
- 必须可以分组聚合的SQL中使用;
- 函数接收多行数据(数据集,如游标、集合、数组等);
- 函数返回一行类型为字符串的数据。
推荐一篇文章,
String Aggregation Techniques
, 内容非常精彩,它演示了在 oracle 中使用 pl/sql 自定义函数来实现的多种方式,分别有数组、游标的情况。还用了 oracle 专用的 connect by、sys_connect_by_path、max() keep (dense_rank order...) 这种显摆的技巧,是学习 oracle pl/sql 编程的不错案例。
本文涉及到数据库分组聚合字符串连接函数,还有递归查询、分析函数、构建简易数据集等方面的知识。
关于递归查询、分析函数,可看本《thinking in sql》系列相关文章