表间关联 | 一次讲清楚
目录
在写 SQL 时,同时操作两个表以上时,就绕不过内联接、左联接。而有时还会看到半联接、全联接、散列联接,这些又是什么呢 ?🤔
本文将列举各种关联方式、多个用途下的术语,它们之间的概念差异,是理解与记忆的关键。
在 《什么是SQL》 中提到,SQL是基于数据集的操作,须使用集合的逻辑来思考。
集合的一些概念与运算 #
集合论属数学的一个分支学科,本小节仅摘取部分内容,用于支持陈述。
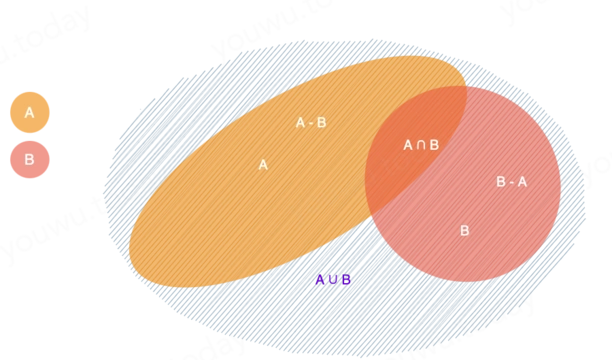
集合是由一组无序且唯一的元素组成。当元素个数为0时,称为空集。集合有以下这些运算规则,交集、并集、差集、补集。
假设有两个集,A、B:
- 它们相交部分称为交集,记为 A∩B={x|x∈A 且 x∈B};
- A与B所有元素合并起来成为一个新集称为 并集,记为 A∪B={x|x∈A,或x∈B};
- A 中存在但不在 B 中,称为A的差集,记为 A-B⊆{x|x∈A,且x∉B} ,A 中不存在但存在于 B 中,称为 A的补集,记为 B-A⊆{x|x∉A,且x∈B} 或 AC 。
集合论的符号
| 符号 | 释义 |
|---|---|
| {} | 表示集合 |
| A ∪ B | 并集,在 A 或/和 B 中的元素 |
| A ∩ B | 交集,在 A 和 B 中的元素 |
| A - B | 差集,在 A 里但不在 B 中的元素 |
| AC | 补集(也称余集),不在 A 的元素 |
| x∈A | x 是集 A 的元素 |
| x∉A | x 不是集 A 的元素 |
数据集与集合的区别 #
关系型数据库本身建立在关系代数理论上。可以把表看成数据行的集合,而数据行则是集合中的元素。但是有些区别:
- 强制性约束:表中的元素(数据行)具有相同的数据结构
- 宽松性约束:表中的元素(数据行)可以重复,除非添加唯一性约束
关联方式 #
有了集与集的运算,我们就可以更加清楚地解释关系型数据库中的表间关联方式。使用“表间关联”,意在突出编写 SQL 时的表间关系分析,它对能否编写出正确 SQL 非常重要。最终会落实为具体的联接方式,也叫联结方式。
在SQL中,联接的方式有 内联接、外联接、左联接、右联接、全联接、交叉联接。
为表达需要,下文仅描述二元关系,以简化过程。
内联接 #
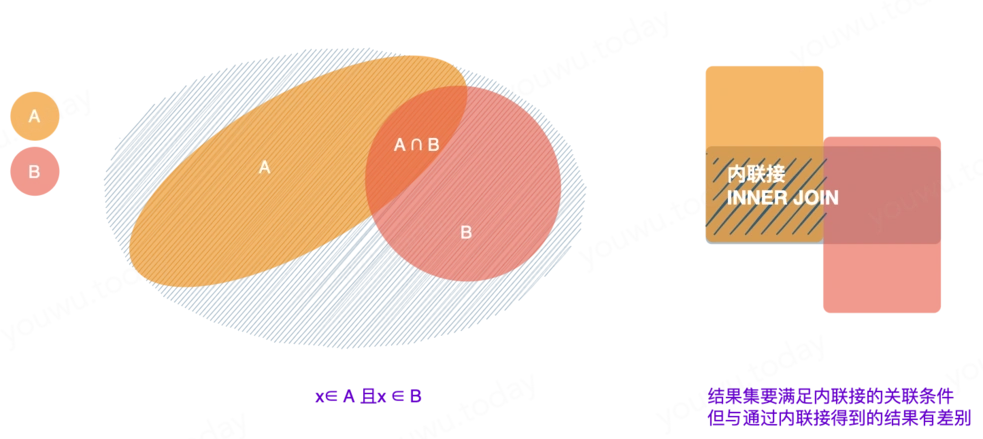
内联接,也叫自然联接。第一个表(类似于上一节中的集A)中的每一行数据,根据关联条件,从第二个表中(上节中的集 B)查找并返回匹配的数据行。对应集的交集运算。

with /* postgres */ ta(seq_1_3) as
( select generate_series(1,3)
), tb(seq_2_4) as
( select generate_series(2,4)
)
select *
from ta
inner join tb
on seq_1_3 = seq_2_4;
两个数据集,{1,2,3}、{2,3,4},使用内联接取共同的部分,得到 {2,3}。 结果为:
seq_1_3 | seq_2_4
---------+---------
2 | 2
3 | 3
(2 rows)
内联接的等价实现:
with /* postgres */ ta(seq_1_3) as
( select generate_series(1,3)
), tb(seq_2_4) as
( select generate_series(2,4)
)
select *
from ta
intersect
select *
from tb;
seq_1_3
---------
2
3
(2 rows)
⚠️ 开卷:
- 如果你已经接触到性能分析,那么,等价实现是否意味着执行计划就相同呢?
外联接 #
除内联接外,其它左联接、右联接、全联接,都属于外联接。因外联接有谁关联谁的先后之分,或者主从之分,因此引入驱动表与关联表的术语,驱动表表示以谁为主。`
在 SQL-92 标准中,已经定义了
left join与left outer join、right join与right outer join、full join与full outer join均为同义。千万别让人给无厘头了。

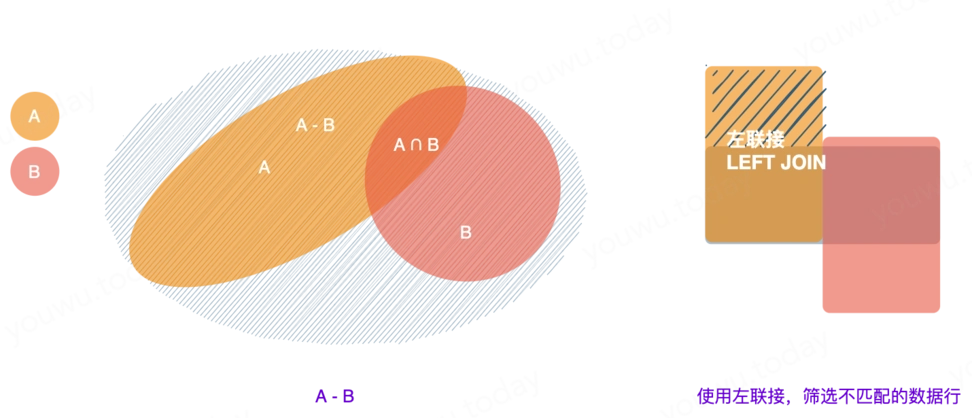
- 左联接
- 驱动表的每一行数据与关联表的数据行匹配,返回驱动表的所有数据行与满足联接条件的关联表数据行。没有匹配上,关联表对应的列位填
NULL。
with /* postgres */ ta(seq_1_3) as
( select generate_series(1,3)
), tb(seq_2_4) as
( select generate_series(2,4)
)
select *
from ta
left join tb
on seq_1_3 = seq_2_4;
结果为:
seq_1_3 | seq_2_4
---------+---------
1 |
2 | 2
3 | 3
- 右联接
- 驱动表的每一行数据与关联表的数据行匹配,返回关联表的所有数据行与满足联接条件的驱动表数据行。没有匹配上,驱动表对应的列位填
NULL。右联接与左联接,正好是驱动表、关联表对换。
with /* postgres */ ta(seq_1_3) as
( select generate_series(1,3)
), tb(seq_2_4) as
( select generate_series(2,4)
)
select *
from ta
right join tb
on seq_1_3 = seq_2_4
结果为:
seq_1_3 | seq_2_4
---------+---------
2 | 2
3 | 3
| 4
- 全联接
- 全联接是指返回驱动表与关联表的所有数据行,满足关联条件数据行,联接为同一行。不满足关联条件而无匹配的,使用
NULL填补对应列位。
with /* postgres */ ta(seq_1_3) as
( select generate_series(1,3)
), tb(seq_2_4) as
( select generate_series(2,4)
)
select *
from ta
full join tb
on seq_1_3 = seq_2_4;
结果为:
seq_1_3 | seq_2_4
---------+---------
1 |
2 | 2
3 | 3
| 4
(4 rows)
全连接的等价实现
with /* postgres */ ta(seq_1_3) as
( select generate_series(1,3)
), tb(seq_2_4) as
( select generate_series(2,4)
)
select *
from ta
left join tb
on seq_1_3 = seq_2_4
union
select *
from ta
right join tb
on seq_1_3 = seq_2_4
⚠️ 开卷:
- 左联接对应集合的哪些运算?
select * from ta minus select * from tb,看得到什么结果?- 知道左联接为什么叫“左联接”了吗?
交叉联接 #
大部分情况下,使用 内联接、左联接 就可以解决问题。不过有时会出现这样的需求,比如我们需要快速构建一个 5 × 5 行的测试集,正好是两个分别具有5行数据的表或子查询无条件关联可以得到的。这正是交叉联接,也称为笛卡尔联接。

交叉联接,第一张表的每一行数据联接第二张表的所有数据行,得到的结果集行数两表的记录行数之乘积。当的到交叉联接或者缺少关联条件时,你的第一反应应该是质问该处是否正确,检查 SQL查询要回答的业务问题,因为需要使用到交叉联接的场景实在比较少。
with /* postgres */ ta(seq_1_3) as
( select generate_series(1,3)
), tb(seq_2_4) as
( select generate_series(2,4)
)
select *
from ta
cross join tb;
-- or
with /* postgres */ ta(seq_1_3) as
( select generate_series(1,3)
), tb(seq_2_4) as
( select generate_series(2,4)
)
select *
from ta, tb;
结果为:
seq_1_3 | seq_2_4
---------+---------
1 | 2
1 | 3
1 | 4
2 | 2
2 | 3
2 | 4
3 | 2
3 | 3
3 | 4
(9 rows)
⚠️ 开卷:
- 你是否用对了 笛卡尔 这个词呢?
联接的实现方式 #
前文解释了联接方式(内联接、外联接),用来表示数据集间的关系与关联操作,是用户指定数据范围逻辑,影响查询结果,它也被定义在 SQL 标准中。而数据库中具体这些标准时,底层的工作原理是怎么样的呢?难道仅仅是逐条数据逐行匹配的循环吗?
因涉及数据库内部实现,具体内容依赖于商业闭源数据库厂商的公开资料、产品文档,开源数据库的文档或代码,本节仅针对 oracle 数据库的几种具体实现作介绍。这些实现方式是 oracle 数据库优化器最终为SQL执行选择的具体执行方法,并不是由用户来确定的。它们分别有不同的性能特点与适用场景。不过oracle还是提供了提示来强制执行,用于在优化中固定SQL的执行计划。
为区别内联接、外联接,以联接方法来称呼这些底层的联接实现。oracle 的联接方法有: NESTED LOOP JOIN(嵌套循环联接)、SRORT-MERGE JOIN(排序合并联接)、HASH JOIN(散列联接)。
NESTED LOOP JOIN #
NESTED LOOP JOIN,嵌套循环联接,顾名思义,嵌套的循环。外循环遍历驱动表的每一行数据,驱动表的每一次数据从关联表中逐行匹配开成内循环。
select
from 表1
inner join 表2
on 关联条件
where 表1的过滤条件
使用伪代码的形式可以表示为:
for 每一行 in (select * from 表1 where 表1的过滤条件)) {
for row in (select * from 表2 where 外层关联条件 ) {
if 匹配 then {行传给下一步骤}
}
}
嵌套循环联接实现,一般编程语言中的 for循环 非常类似,复杂度受表的记录数多少而受影响。它可以非常快的开始返回结果。当数据量非常少时,这种方法是最快的,每一行数据只处理一次,使用的内存也非常少。
SORT-MERGE JOIN #
SORT-MERGE JOIN,排序-合并联接,由排序与合并的一对操作。oracle 独立的读取需要联接的两表,对每张表的数据行(满足过滤条件的数据行)按照联接字段排序,然后将排序后的数据行集合并。这种联接方法的排序开销非常大,对于无法整表放入内存的,可能会使用临时磁盘空间完成排序。因此它非常占内存和时间资源。当排序完成后,合并过程非常快。数据库轮流操作两个列表,比较最上面的数据行,丢弃排序队列中比另一列表中的最前面还早的数据行,并返回匹配行。
排序-合并联接一般适合筛选条件有限并返回有限数据行的查询。如果没有可用的直接访问数据的索引,那么排序-合并联结通常是较好的选择。在条件为非等式时,排序-合并联接通常是最好的选择。
HASH JOIN #
hash join,散列联接。先应用条件筛选,单独读取两张准备联接的表,基于统计信息,将预测可能返回最少行数的表散列化到内存中。它个散列表包了原表的数据行,并基于联接字段转化的散列值的随机函数载入到散列桶中。这个散列表一直放在内存,若没有足够的内存,散列表会被写入临时磁盘空间。
数据库读取另一较大的表,并对联接字段应用散列函数,然后根据得到的散列值,在内存中的散列表进行探测,与匹配到的散列桶中的数据行列表(这个数据行列表的数据来自被散列化的表)进行联接条件匹配,若匹配碾,则返回一行数据,否则丢弃。较大的表(没有被散列化到内存)只读取一次,并检查它每一行数据是否匹配。它与嵌套循环联接的不同在于,内层匹配的算法不同,散列联接的内层表(散列化到内存中的)会多次被探测。
当数据行较大,并且结果集也较大时,最好考虑散列联接。
散列联接只有在相等联接的情况下才能进行,原因在于匹配是针对散列值进行,而在一个范围内(大于、小于、between and )对于散列值没有意义。出现非等式条件,改用排序-合并联接。
半联接与反联接 #
半联接(SEMI JOIN)与反联接(ANTI JOIN),是oracle 数据库的优化器选择用来如何定位数据的方法,不是SQL语法的一部分。
半联接 #
半联接,是在两个数据表之间的联接,根据另一个表中的数据是否出现或者不出现相匹配的数据数据行,来决定第一个表中的数据行是否返回。
维恩图无法正确表示“存在于”这种半联接,因此只能近似表达,并加以约束说明。
从定义上看,半联接需要判断的是“出现或者不出现相匹配”,而不是匹配的所有行,因此,拿前文的集合的运算(维恩图)或者内外连接来等价表示就不够严谨准确。它与标准的联接的主要区别在于,半联接中,第一个表的每一条记录只返回一次,不管第二个表有几条匹配数据,则第一个表的每一条符合筛选条件的数据,对第二个表进行探测,只要发现有匹配的,即返回;然后再以相同的逻辑遍历第一个表的其它数据行。
为了方便理解,你可认为它是联接的一种选项,或者简化形式,这正是“半”之所在。它通过停止多余的探测来优化执行时间。
说到这里,你可能已经明白,我们写SQL时出现的 IN、EXISTS 就是半联接。
-- 没有oracle 环境,此处使用 postgres 仅用于示意
with /* postgres */ ta(seq_1_3) as
( select generate_series(1,3)
), tb(seq_2_4) as
( select generate_series(2,4) union all
select generate_series(2,4)
)
select *
from ta
where seq_1_3 in (select seq_2_4 from tb);
判断 ta 子查询 {1,2,3} 出现在 tb 子查询 {2,2,3,3,4,4} 的元素。虽然 tb 中有重复元素,但不会影响结果(出现重复)。例中 seq_1_3 in 也可写为 seq_1_3 = any。
seq_1_3
---------
2
3
(2 rows)
本例使用 exists 可写为:
with /* postgres */ ta(seq_1_3) as
( select generate_series(1,3)
), tb(seq_2_4) as
( select generate_series(2,4) union all
select generate_series(2,4)
)
select *
from ta
where exists (select 1
from tb
where tb.seq_2_4 = ta.seq_1_3);
使用 标准联接 inner join 的写法,注意,由于内联接会受两个表中所匹配的数据行记录数影响,因为并不完全等价,需要对查询二次加式(distinct)才能完全等效。不过,distinct 并不是万能的,它会对整个结果集去重,如果此时来自驱动表的数据行源本身就是重复的,此时就不等价了。
with /* postgres */ ta(seq_1_3) as
( select generate_series(1,3)
), tb(seq_2_4) as
( select generate_series(2,4) union all
select generate_series(2,4)
)
select distinct ta.*
from ta
inner join tb
on tb.seq_2_4 = ta.seq_1_3;
使用集相交 intersect方法,以 ta 为驱动表与 tb 求交集,所得结果与 ta 再进行等值连接,可写为:
with /* postgres */ ta(seq_1_3) as
( select generate_series(1,3)
), tb(seq_2_4) as
( select generate_series(2,4) union all
select generate_series(2,4)
), tc(seq_1_3) as
( select * from ta
intersect
select * from tb
)
select ta.*
from ta
inner join tc
on ta.seq_1_3 = tc.seq_1_3;
反联接 #
反联接在本质上,与半联结相同,是嵌套循环、散列、合并联接的优化方法,是优化器选择的选项之一,不是特定SQL语法可以调用的。它返回的数据与半联接相反。用集合中的术语来描述,反联接可以定义为半联结的补集。
反联接,如何右侧没有对应匹配的数据行,则返回左侧数据行。因为反联接的结果正好与半联结相反,因此我们自然就能联想到 not in、 not exists上来。
with /* postgres */ ta(seq_1_3) as
( select generate_series(1,3)
), tb(seq_2_4) as
( select generate_series(2,4) union all
select generate_series(2,4)
)
select *
from ta
where seq_1_3 not in (select seq_2_4 from tb);
从 ta 中找到不存在于 tb 中的数据行,结果为:
seq_1_3
---------
1
(1 row)
使用 not exists 可改为:
with /* postgres */ ta(seq_1_3) as
( select generate_series(1,3)
), tb(seq_2_4) as
( select generate_series(2,4) union all
select generate_series(2,4)
)
select *
from ta
where not exists
( select 1
from tb
where tb.seq_2_4 = ta.seq_1_3);
使用 left join 可写为:
with /* postgres */ ta(seq_1_3) as
( select generate_series(1,3)
), tb(seq_2_4) as
( select generate_series(2,4) union all
select generate_series(2,4)
)
select ta.*
from ta
left join tb
on tb.seq_2_4 = ta.seq_1_3
where tb.seq_2_4 is null;
使用 集合差集运算 minus ,可写为(postgres 中的 minus 的替代关键字为 except):
with /* postgres */ ta(seq_1_3) as
( select generate_series(1,3)
), tb(seq_2_4) as
( select generate_series(2,4) union all
select generate_series(2,4)
), tc(seq_1_3) as
( select * from ta
except
select * from tb
)
select ta.*
from ta
inner join tc
on ta.seq_1_3 = tc.seq_1_3;
小结 #
本文将涉及到联接的概念做一次完整的梳理,其中有SQL标准中的联接谓词,也有数据库底层实现的联接方法。特别注意的,关于 oracle 的排序合并联接、嵌套联接、HASH联接,涉及到 oracle 的优化,如果 oracle 是你未来主要使用的数据库,那么请选择与优化相关的文档或书籍,本文中的内容过浅,不能满足你的需求。
| 联接 | 用途 |
|---|---|
| inner join | 内联接,两个数据集中满足匹配条件的部分 |
| left join | 左外联接,驱动表数据,以及被匹配的关联表数据 |
| full join | 全外联接,两个关联的数据集 |
| hash join | oracle 优化器中的一种关联实现 |
| sort-merge join | oracle 优化器中的一种关联实现 |
| nested join | oracle 优化器中的一种关联实现 |
| semi join | oracle 优化器中的一种关联实现优化选项 |
| anti join | oracle 优化器中的一种关联实现优化选项 |
⚠️ 开卷:
- 在你熟悉的数据库中,编写两个表关联的SQL,分别测试“大表-大表”、“小表-小表”、“大表-小表”三种情况,通过 explain 查看执行计划,并分析这三种情况的计划是否有差异?有什么差异?
- 分别编写 in、exists、not、not exists 的SQL,观察执行计划中给出了什么步骤,反推数据库中的实现方法?