- /
- Skills/
- 后端编程/
- 使用ferret工具爬取网络数据/
使用ferret工具爬取网络数据
目录
本文介绍使用 ferret 工具实现网络数据、网页数据的爬取。ferret 有别于 scrapy,它通过它提取的 DSL 来定义数据的爬取逻辑。所以,与爬取数据时,在 scrapy 中定义数据源连接、数据处理 pipeline 不同,使用 ferret 的爬取过程被使用 ferret query language 脚本来描述,并通过 ferret 提供的 runtime 运行时环境来解析与执行该脚本。
ferret 的简单介绍 #
ferret,是一个由 go 实现的开源网络爬虫工具,官方网站 www.montferret.dev 。
通常,使用 scrapy、colly 等热门爬虫编程框架,是在 python、go 等编程语言环境中,通过写程序的方式,使用 scrapy 或 colly 提供数据爬取场景下常用函数与固定的程序结构,来定义数据爬取过程。
而 ferret 却非常不同,它抽象了数据爬取过程,尝试提供了一种编程无关的通用查询语言 ferret query language(简称 fql ),来简化数据爬取的过程定义,让不懂程序的用户也可轻松学会如何爬取网络数据。
当然,表面上 ferret 与编程无关,其实编写 fql 查询脚本,也是一种编程过程,只不过它不要求使用者具备高深的编程技能。fql 与编程环境无关,使用文本编程器则可以编写。ferret 还提供了一个在线测试环境来编写 fql 。
从 ferret 网站上的说明来看,作者是一位经常与爬虫打交道的工作者,日常需要编写非常多的爬虫程序。为了更快速、更简单的完成工作,设计并实现了 ferret。目前 ferret 还比较年轻,截至编写本文时,它的最新版本为 v0.15.0 。
ferret 下载、安装 #
在使用 ferret 之前,需要安装 ferret 工具,用来解析与执行 fql 脚本。
按照当前(2021年5月5日)官方提供的安装方法,可能你无法正常安装。在官方提供的程序 下载地址 ,找不到最新预编译版本(最新 ferret 库版本为v0.15.0,但带有预编译的版本为 v0.14.0),
如果你熟悉 golang 编程,通过 ferret 的源码也可以编译出可执行程序。
为了方便,建议你从以下这个地址下载,https://github.com/MontFerret/cli/releases/。这是作者提供的命令行工具,已经打包了 ferret,windows\linux\macos 都有对应版本。按照 ferret 的设计,ferret 后续非常可能做为go工具库的形式存在。
从上面地址下载到 ferret cli 后,把压缩包中的 ferret 或者 ferret.exe 放到命令行可以解析到的 path 中。
- macos 、linux 用户可以将 ferret 可执行程序文件放到如
/usr/local/bin路径下 - windows用户,可以放到你系统环境变量
%path%下已配置的路径下,或者自己添加一个路径到%path%
如何抓取数据 #
使用 ferret 与 使用 scrapy 框架的过程类似,都是连接到网络,访问指定 url 地址下载数据后,并进行数据处理后输出结果。
ferret 爬取数据方式有两种:
- 访问 json 数据源,提取需要 field 后输出
- 访问 html 网页,使用 querySelector 查找所需的 element 元素并提取数据
官方网站上有几个常用场景(如翻页、iframes)的例子, cockbook 。
json 示例 #
爬取 json 数据的 fql 一般性结构:
// 获取数据
let data = json_parse(io::net::http::get( url 地址))
// 定义输出
for i in data:
result {
i.json 的 filed
}
使用 io::net::http::get 获取数据(字节数组)后,使用 json_parse 转化为 json 格式,提取所须的字段输出。下面是抓取知乎热榜的例子,
假设:
json api: "https://www.zhihu.com/api/v3/feed/topstory/hot-lists/total?limit=10"
json 结构:
data:
- detail_text:
id:
target:
url:
title:
在本地创建一个文本文件 zhihu.fql,写上以下内容:
// 知乎热榜 fql,不过滤
let url = "https://www.zhihu.com/api/v3/feed/topstory/hot-lists/total?limit=10"
LET json = JSON_PARSE(
IO::NET::HTTP::GET({
url
}))
return json
使用 ferret cli 在命令行执行:
ferret exec zhihu.fql > zhihu.json
把生成的 zhihu.json 拖到火狐浏览器或者 json 编辑器上看下效果,内容非常长。
添加上过滤之后,再看看效果:
// 知乎热榜 fql 过滤
let url = "https://www.zhihu.com/api/v3/feed/topstory/hot-lists/total?limit=10"
LET json = JSON_PARSE(
IO::NET::HTTP::GET({
url
}))
// 获取 json api 返回数据中的某些项
for i in json.data
return {
hot: i.detail_text,
url: substitute(i.target.url, "//api.zhihu.com/questions/", "//www.zhihu.com/question/"),
title: i.target.title,
id: i.id,
}

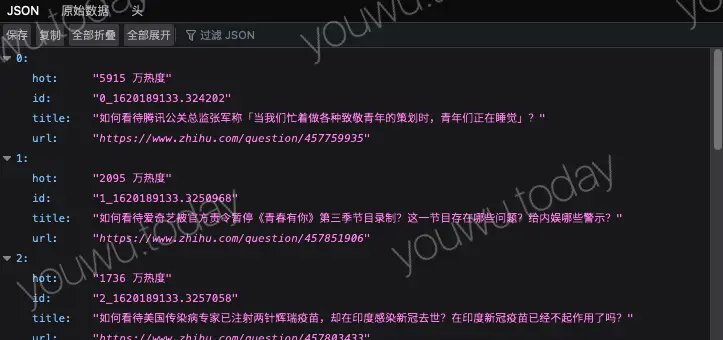
- fql 输出的是程序友好、阅读不友好的紧凑型 json ,需要阅读时,使用 json 格式化工具或者火狐浏览器。
- json 的过滤是使用 for 循环逐行从嵌套结构中取出所需的字段,取数时,应该事先了解 json api 返回的 json 结构。可以先不过滤后再逐步调试。
- 如果你所获取的数据源是 json 结构的,fql 对 json 的支持非常友好,可以通过".“符号方式,来获取多层嵌套的数据。
html 示例 #
爬取 html 数据的 fql 一般性结构:
// 获取数据
let doc = DOCUMENT(URL)
// 定义输出
for i in data:
各种 query selector 或转换
与抓取 josn 数据类似,但由于 html 更加复杂,获取到的是一个 html document,需要进步一格式化或者查询才能获取真正所需的数据内容。
下面是访问微博热搜并提取数据的例子,
假设:
页面url: "https://s.weibo.com/top/summary?cate=realtimehot"
页面关键结构:
"#pl_top_realtimehot table tbody tr":
td-01 ranktop:
td-02:
a
span
td-03:
在本地创建一个文本文件 weibo.fql,写上如下内容:
// 微博热搜
let url = ""
let ua = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:87.0) Gecko/20100101 Firefox/87.0"
LET page = DOCUMENT(url, {
userAgent: ua
})
let selector = '#pl_top_realtimehot table tbody tr'
//tr:
// td-01 ranktop:
// td-02:
// a
// span
// td-03:
for e in ELEMENTs(page, selector)
filter ELEMENT_EXISTS(e, '.td-01.ranktop')
let title = inner_text(e, '.td-02 a')
// let
return {
ord : inner_text(e, '.td-01'),
cnt: inner_text(e, '.td-02 span'),
title: title,
url: search_url + title + "&Refer=top",
hot : inner_text(e, '.td-03'),
}
保存 weibo.fql,使用 ferret cli 在命令行执行:
> ferret exec weibo.fql > weibo.json
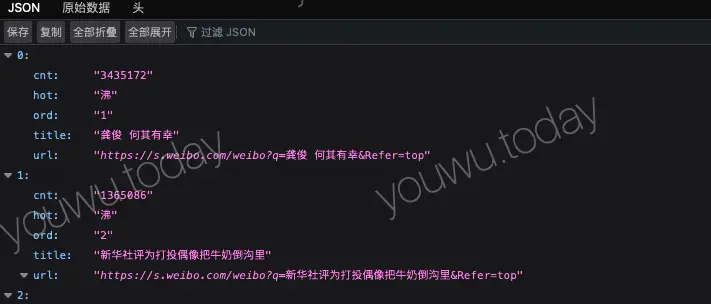
注意,使用 DOCUMENT 函数查询页面时,可能因为当前版本的 ferret 还处于早期的开发阶段,会打印 debug 信息,如果使用上面
ferret exec weibo.fql > weibo.json的方式执行得到的weibo.json,需要删除掉第一行才是一个正确格式的 json。有一种方式可以完美解决这个问题,请看下文 『fql 查询结果另存为』。
fql 脚本的一般说明 #
官方提供了详细的 ferret query language 的说明, fql 。
内容大体可以分为:
- fql 语法
- fql 操作过程中的数据类型
- fql 的数据操作符,如循环、过滤、排序
- fql 标准函数库,如上面章节例子中使用的
IO::NET::HTTP、DOCUMENT等,需要熟悉其中的函数,这样才能写好 fql 脚本
经测试,目前 fql 中的函数大小写并没有区别,使用者根据自己习惯统一风格即可。
在编写 fql 时,可以使用在线测试环境来辅助调试, montferret.dev/try/
fql 查询结果另存为 #
上面的 html 示例中提到,执行 ferret cli 时会提示调试信息,这些信息并不是我们要的结果,那么使用命令行重定向的方式不能区分,会把终端输出全部当成结果。这时可以在 fql 脚本中使用 io::fs::write来保存想要的结果。
在上面的示例中,添加如下格式的fql:
// 获取数据
let doc = DOCUMENT(URL)
// 定义输出
let result = (
for i in data:
各种 query selector 或转换
)
io::fs::write("结果文件名.json", result)
return 0
则,使用 let result=() 把整个 for 循环包裹起来,这时整个查询的输出都存在 result 变量,通过 io::fs::write 写到本地文件。
这样,聪明的同学已经想到,是不是可以把多个查询全部放到一个 fql 脚本中,通过 io::fs::write 分别写到不同的文件来保存结果,这样就可以实现一次执行获取多个结果?
是的,不过建议,一个 fql 脚本编写一个查询,这样方便维护管理,ferret cli 是 go 写的命令行程序,每次启动时的时间比较短,执行一次查询的真正时间大约都是几百毫秒,主要的时间花在网络访问上,不是数据处理。
延伸 #
如果你是 go 语言开发者,可以像使用 ferret cli 使用 ferret 一样,把 ferret 当成库来使用,把它嵌到你的程序,让你的程序也可以解析执行 fql。