分析函数 Analytic Function
目录
Analytic Function,分析函数,也叫窗口函数(对应英文名为 window function),数据库产品中的命名并不统一。不过功能、语法规则比较一致。
分析函数是查询语句除了顺序外,最后执行的操作。它对与当前行存在某种联系的一组数据行执行计算(这不是定义,只是行为描述)。与聚合函数可以完成的计算类似,但分析函数与聚合函数又有明显不同,聚合函数返回的结果是基于分组的单个数据行,而分析函数为每个分组返回多行结果,每个结果行对应一行原数据行,且分析函数的分组可以为聚合函数的分组的不完全部分。其中分析函数带有一个描述与当前行关系的数据范围语句,称之为 窗口,或者说分析函数必须有一个描述滑动窗口中的语句。这也是分析函数被称为窗口函数的原因。
⚠️ 从字面上,很又难理解,可以多看几遍。
我们经常使用的聚合函数,大多都有对应的分析函数版本。
analytic_func(...)
over( partition by ... [order by ...])
不同数据库产品为分析函数的子语定义了不同的名称,如 oracle 数据库将 over(...) 叫为 analytic_clause 分析子语,而 postgres 数据库将 over(...) 称为 window_definition 窗口定义。不论使用使用名称,它们均由这几部分组成。
分析函数 := 函数名([参数]) over([分组表达式] [排序表达式] [移动范围])
分组表达式 := partition by 表达式 [,...]
排序表达式 := order by 表达式 [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [,...]
frame子语 := { RANGE | ROWS } frame
| { RANGE | ROWS } BETWEEN frame AND frame
frame := { UNBOUNDED PRECEDING
| CURRENT ROW
| value_expr PRECEDING
}
分析函数所实现的功能:
- 在查询结果上,进行二次(second pass)计算。也就是说,分析函数访问的数据,是查询结果。可以把它想象成针对结果子查询的再查询。
- 实现 跨行 访问数据,在窗口范围内进行数据聚合
- 窗口基于分组,有些计算函数还需要指定顺序
- 窗口可以是固定的,也可以是移动的(部分函数支持滑动计算)
分析函数的特点:
- 整个查询最后(在order by 之前)执行的操作
- 分析函数不会改变查询的记录数(与group by分组聚合的区别之一个),数据行保持原有标识
引例 #
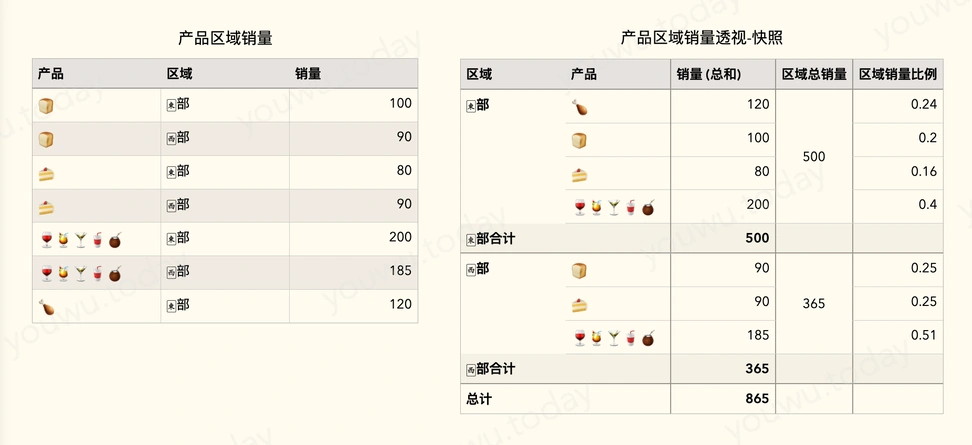
改进 《sql实践:分组聚合 group by》 中区域产品销量统计的例子,在产品区域销量后,添加“区域总销量”、“产品区域销量比例”等计算列。
--通用型,code in postgres
with "区域销量" as
(
select "区域"
, sum("销量") as "销量"
from "产品销售明细"
group by "区域"
), "产品销量" as
( select "区域"
, "产品"
, sum("销量") as "销量"
from "产品销售明细"
group by "区域"
, "产品"
)
select prod."区域"
, prod."产品"
, prod."销量" as "销量_产品"
, region."销量" as "销量_区域"
, prod."销量" / region."销量" as "区域销量比例"
from "产品销量" as prod
inner join "区域销量" as region
on prod."区域" = region."区域"
order by 1, 2
;
| 区域 | 产品 | 销量_产品 | 销量_区域 | 区域销量比例 |
|---|---|---|---|---|
| 🀀部 | 🍗 | 120 | 500 | 0.24000000000000000000 |
| 🀀部 | 🍞 | 100 | 500 | 0.20000000000000000000 |
| 🀀部 | 🍰 | 80 | 500 | 0.16000000000000000000 |
| 🀀部 | 🍷🍹🍸🥤🧉 | 200 | 500 | 0.40000000000000000000 |
| 🀂部 | 🍞 | 90 | 365 | 0.24657534246575342466 |
| 🀂部 | 🍰 | 90 | 365 | 0.24657534246575342466 |
| 🀂部 | 🍷🍹🍸🥤🧉 | 185 | 365 | 0.50684931506849315068 |
若使用分析函数,查询SQL可以这样写:
--使用分析函数方式1,code in postgres
with "产品销量" as
(
select "区域"
, "产品"
, sum("销量") as "销量"
from "产品销售明细"
group by "区域"
, "产品"
)
select "区域"
, "产品"
, "销量"
, sum("销量") over (partition by "区域")
as "区域总销量"
, "销量"/
sum("销量") over (partition by "区域")
as "区域销量比例"
from "产品销量"
;
甚至可以写成:
-- 使用分析函数方式2,code in postgres
select "区域"
, "产品"
, sum("销量") as "产品销量"
, sum(sum("销量")) over (partition by "区域")
as "区域销量"
, sum("销量")
/ sum(sum("销量"))
over( partition by "区域" ) as "区域销量比例"
from "产品销售明细"
group by "区域"
, "产品"
;
例中,普通型SQL构建不同分组汇总的多个子查询后,通过“区域”将子查询关联起来,从而使 (区域, 产品) 分组数据行可以访问到 (区域) 分组对应的销量来计算销量比例。
虽然可以使用 rollup 函数也可以计算得到*(区域)* 分组的销量汇总,但结果行与*(区域, 产品)* 分组汇总结果并行,无法跨行访问。
还可以将 sum(...)over(...) 改为 avg(...)over(...) 统一计算平均销量,这样就可以拿每个产品的区域销量与产品平均销量在同一数据行内进行比较。
分区 #
为避免与 group by 分组混淆,这里使用 分区。
例 分析函数方式1 中,产品销量 是 (区域, 产品) 分组的结果行集合。sum("销量") over (partition by "区域") 在结果集上,按 (区域) 划分分区,相当于分组后结果集上的分区,这个分区就是窗口。分析函数之所以被称为窗口函数,就在于这个特性,从数据集上划分出一个范围。
二次计算 #
例 分析函数方式2 中,最能体现出二次计算(分析函数在整个SQL查询的最后,排序之前)。在聚合*(区域)* 分区计算“区域销量”时,使用了 sum(sum("销量")) over (partition by "区域"),而不是sum("销量") over (partition by "区域")。注意,本例是一个 group by 分组聚合查询,sum("销量") 是 (区域, 产品) 分组的聚合结果,即“产品的区域销量”,要去掉“产品”升级到“区域”才能汇总出“区域销量”。sum("销量") 恰好是查询的选择列(结果列),分析函数是针对结果列进行的最后计算,因此要使用 sum(sum("销量")) over(...)。即使你使用 sum("销量") over(...),数据库会检测到 销量 字段不是 group by 语句上的字段,或者结果行不同分组标识的字段,应无法计算而报错。
你刚开始使用分析函数时,可能无法直接写出 sum(sum("销售")) over(...) 形式,那可以把它想象成:
"产品销量" := sum("销量")
"区域销量" := sum(产品销量) over(partition by "区域")
另,若没有声明分区,即聚合函数() over(),即把整个查询结果当成一个分区进行聚合计算。
排序 #
一些分析函数的计算跟排序有关,比如计算排名。
-- coded in postgres
with "产品销量" as
(
select "区域"
, "产品"
, sum("销量") as "销量"
from "产品销售明细"
group by "区域"
, "产品"
)
select "区域"
, "产品"
, "销量"
, rank() over(partition by "区域" order by "销量" desc) as "区域销量排名"
, rank() over(order by "销量" desc) as "全域销量排名"
from "产品销量"
;
| 区域 | 产品 | 销量 | 区域销量排名 | 全域销量排名 |
|---|---|---|---|---|
| 🀀部 | 🍷🍹🍸🥤🧉 | 200 | 1 | 1 |
| 🀂部 | 🍷🍹🍸🥤🧉 | 185 | 1 | 2 |
| 🀀部 | 🍗 | 120 | 2 | 3 |
| 🀀部 | 🍞 | 100 | 3 | 4 |
| 🀂部 | 🍞 | 90 | 2 | 5 |
| 🀂部 | 🍰 | 90 | 2 | 5 |
| 🀀部 | 🍰 | 80 | 4 | 7 |
偷偷说一句,由于oracle数据库的select语句,不支持 limit N offset N 的语句,需要通过 row_number() over(order by ...) 语法来变通实现,使用的 row_number()函数,正是分析函数。
滑动 #
滑动窗口是指窗口所限定的范围,相对于当前数据行是移动的。上例 “产品销量”并不能体现这个特点。
在区域内,找到当前产品销量排名之后的产品。
with "产品销量" as
(
select "区域"
, "产品"
, sum("销量") as "销量"
from "产品销售明细"
group by "区域"
, "产品"
)
select "区域"
, "产品"
, "销量"
, lead("产品", 1) over(partition by "区域" order by "销量" desc) as "下一个销量较多的产品"
from "产品销量"
;
| 区域 | 产品 | 销量 | 下一个销量较多的产品 |
|---|---|---|---|
| 🀀部 | 🍷🍹🍸🥤🧉 | 200 | 🍗 |
| 🀀部 | 🍗 | 120 | 🍞 |
| 🀀部 | 🍞 | 100 | 🍰 |
| 🀀部 | 🍰 | 80 | |
| 🀂部 | 🍷🍹🍸🥤🧉 | 185 | 🍰 |
| 🀂部 | 🍰 | 90 | 🍞 |
| 🀂部 | 🍞 | 90 |
分析函数的计算函数、与窗口子句组合,还可以演变出其他玩法。具体研究各数据库产品提供的分析函数。
窗口名称 #
当SQL语句比较长,并且窗口定义相同时,可以通过窗口名称来减少代码,引用窗口定义。如:
-- 使用分析函数方式2,code in postgres
select "区域"
, "产品"
, sum("销量") as "产品销量"
, sum(sum("销量")) over (partition by "区域")
as "区域销量"
, sum("销量")
/ sum(sum("销量"))
over( partition by "区域" ) as "区域销量比例"
from "产品销售明细"
group by "区域"
, "产品"
;
使用窗口名称语法,写成:
select "区域"
, "产品"
, sum("销量") as "产品销量"
, sum(sum("销量")) over "w_区域" as "区域销量"
, sum("销量") /
sum(sum("销量")) over "w_区域" as "区域销量比例"
from "产品销售明细"
group by "区域"
, "产品"
window "w_区域" as (partition by "区域")
可以看出,使用窗口名称来复用窗口定义,当SQL中的分析函数引用比较多时,增加了可阅读性、逻辑错误等。
不过,只有在比较新的数据库版本中才支持。如oracle要到 oracle 21c 版本才知道,而当前还有很多人部署着 oracle 11g, 之间还隔着 12c、18c、19c等版本。
各数据库的分析函数语法与所支持的分析函数 #
| 数据库 | 语法 | 函数列表 |
|---|---|---|
| postgres 14 | 语法 | 函数 |
| oracle 11g | 语法 | 函数 |
| oracle 21c | 语法 | 函数 |
| sqlite 3.38.3 | 语法 | 函数 |
| mysql 8 | 语法 | 函数 |