SQL 与 ETL | ETL 程序模式
目录
上篇《SQL 与 ETL | 数据类平台架构》文中,探讨了数据类平台的架构,以及架构方案落地过程的路径、资源等,使得我们有了初步认识。SQL 在 ETL 过程、BI数据可视化领域,有举足轻重的地位,它是这些阶段中的基础能力与重要工具,了解数据类平台的架构以及过程,有助于我们找准位置。本文将续上篇文章的内容,谈谈 ETL 程序模式,从中,你将感受到SQL在ETL程序中所发挥的主要功能。
ETL程序在数据流中发挥的作用 #
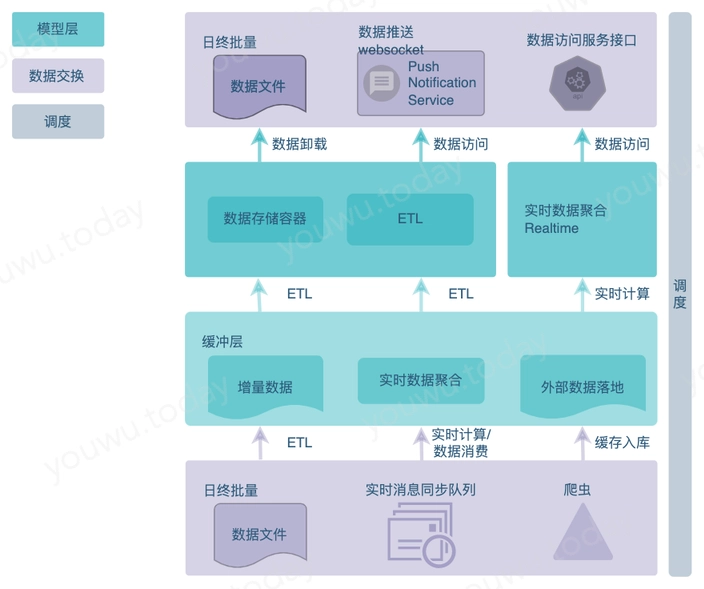
在谈 ETL 程序模式之前,先梳理ETL程序从源到数据消费的整个 pipeline 过程,ETL程序的主要作用有:
- 从数据源载入数据,或数据源主动卸载数据
- 数据转换(并不明显,它体现在程序的业务逻辑实现中)
- 数据模型的加载、数据填充
- 数据集成区的数据卸载
- 实时数据引擎的流式计算
除 实时数据引擎的流式计算外,其它均为传统集中式数据仓库的经典戏码。
ETL 虽有 extract、translate、load 三个动作,有时却不明显。在总结程序模式时,有悟隐藏 translate 转换逻辑细节,并将 ETL 过程分解成一个个单独的 源->目标 单元程序。数据开发、或者早期称呼为 ETL 工程师的大部分日常,由开发这类单元程序工作所组成。本文所要谈的程序模式,指单元程序的模式。单元程序也叫作业。
etl 程序模式化的实际意义 #
我们搞 ETL 程序模式化,不是为像 java 的 GOF 显摆技术。实际上,熟悉数据开发的人员均有类似的感受,数据开发工作需要编写的代码量极少,从业时间愈长,编程能力退化愈发严重,与应用系统开发的技术人员无法相比。
程序模式化,有助于我们认清 ETL程序的结构,减少人为错误,可以把更多的精力、注意力放在构建完整的数据管道上面。另外,构建 ETL 数据管道时,通常大量的时间梳理源、目标的映射关系,这些关系可以概括为 一对一、多对一,其中简单的关系映射占比超过一半以上。
通常我们使用电子表格作为载体来记录这些映射关系。这些映射关系的形式,是有规律的。这种规律正好可以用来建立对应的 ETL 程序模式。自然而然,可以往代码生成方向上走。关于代码生成如何实现,有悟介绍了一种常用方式,请看:
在动手编写 ETL 单元程序之前,先从整体上分析梳理每个目标表的映射源,根据数据源全增量方式、表结构种类来判断表的加载策略,为每一种策略定制一个程序模板,利用表、字段、映射关系信息,就可以使用程序生成程序、脚本生成程序的代码生成来帮助完成大部分代码编写工作,也叫代码自动化。
若仔细分析,大概会发现这种现象,在数据架构中,越靠近数据源的,它的映射关系越简单,一对一完整的数据复制非常常见。而越往上层应用靠拢,关系越复杂,甚至会感到使用电子表格来表示映射关系非常吃力。

代码生成,只是为了提高整体的开发效率、减少人为错误,并不是用来替代开发人员。只要完成大部分有规律的程序生成足已。
etl 程序模式 #
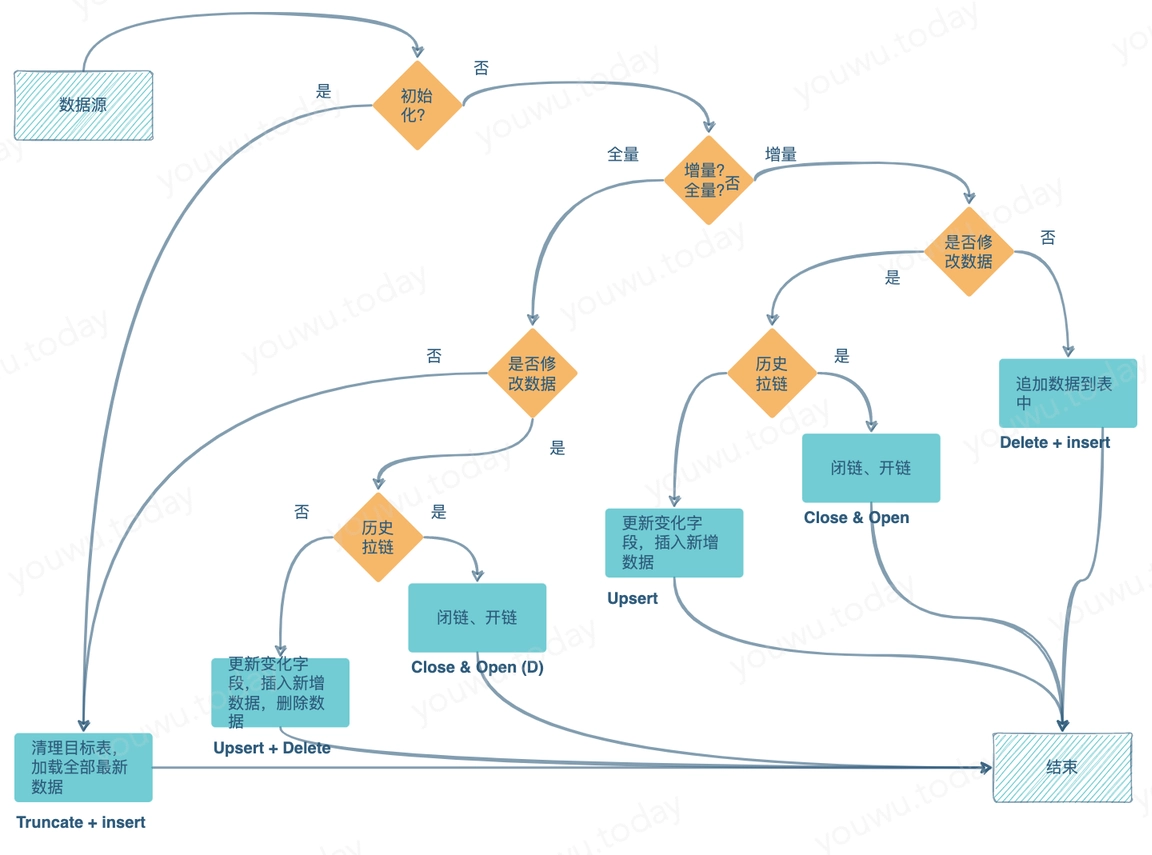
一般性原则: 因代码组织与管理的关系,一个 ETL 单元程序或者作业,通常对应一个加载目标。但若多个目标表加载的取源逻辑相同,这时会合并为一个作业(如果工具支持的话),类似于 oracle 的 insert all,insert into multiple tables ,向多个表分条件插入。
todo,插图
etl 程序分为增量加载、全量加载,这样描述并不严谨。程序模式受 extract(准备加载的数据源)与 load(目标表)的结构、数据保存设计的影响。
数据表结构的种类 #
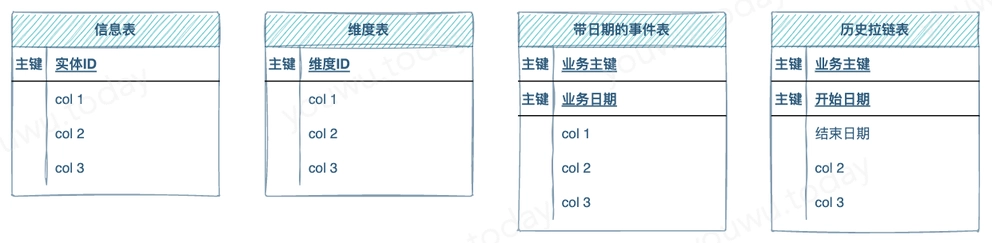
在数据平台中,数据表结构种类有以下几类:
- 带业务主键(可以多个字段)信息表
- 带ID标识的维度表(码值或数据字典)
- 业务主键包含数据日期的数据表,用于保存历史
- 历史拉链表,属上面 类型“3” 的变种, 除可节省存储空间外,保存数据完整的生命周期
针对不同结构类型的表,要在加载完毕后,表示最新时点或者最完整的数据状态,要采用不同的加载步骤。
⚠️ 开卷:
- 保留数据的历史,可以使用哪种类型的表结构
- 什么样的数据需要保留历史?
数据源提供方式 #
单元程序所依赖的数据来源可以有多个,可能是文件,也可能以数据表的形式存在。将这些数据加载到目标表的过程中,可能直接将数据覆盖掉目标,也可能先与目标比较出有变化的数据,再采取一定的策略将目标中的数据替换掉。
因此前文所说的 “etl 程序分为增量加载、全量加载”,是不完全准确的说法,增量、全量仅指相对于目标表是否有无变化,并无指明数据源提供全量、增量。这个因素会影响单元程序的结构。
etl 程序模式 #
根据摄取到的全量、增量数据源,以及目标表结构种类,为达到表示最新数据状态的目的,可以总结出以下几种 ETL 单元程序模式。
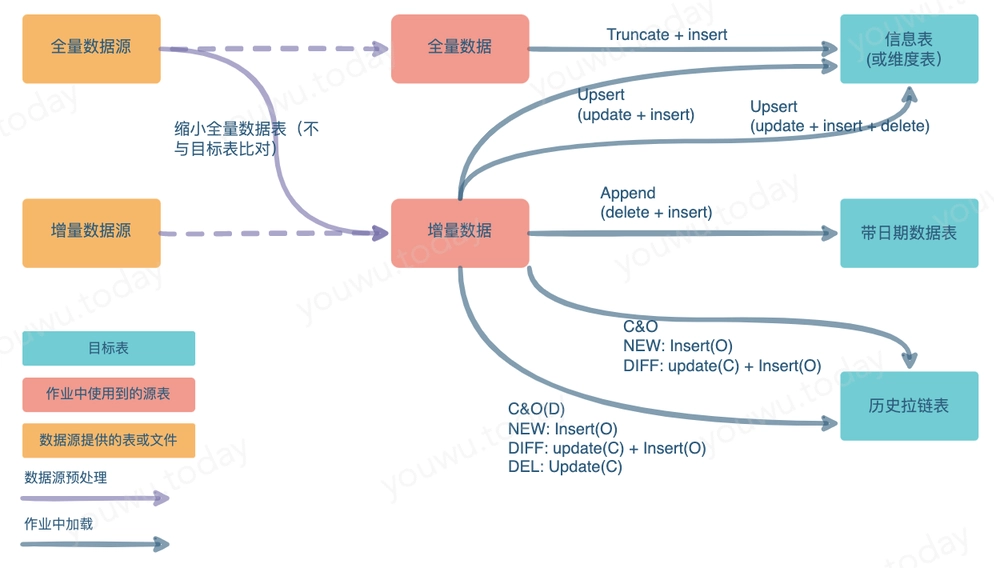
如图所示,单元程序中使用到的源表,有可能直接来自数据源,一一对应,也有可能需要经过一定的预处理。在编制作业时,所引用的具体表或者文件,数据结构有可能与源存在差异。比如,缺少部分字段,或者源系统提供的数据文件过大、无法提供增量需要先预处理等等。预处理过程,也可以认为是“源->目标”的一种模式。不过,它并没有被包含到本文中的ETL程序模式。
| 加载策略名称 | 其它称呼 | 源 | 目标 | 加载 | 策略说明 |
|---|---|---|---|---|---|
| truncate + insert | 替换、replace | 全量 | 信息表、维度表 | 全量 | 替换模式,清空目标表,再 insert 或者 load |
| delete + insert | 追加、append | 增量 | 带日期的数据表 | 增量 | 追加模式。先部分删除,再 insert 或者 load。如按日期删除目标表中数据,多用于重跑 |
| update + insert | upsert | 增量、全量 | 信息表 | 增量 | 比较数据与目标表数据: 若in SOURCE and not in TARGET,则 INSERT ;若source ≠ target ,则 UPDATE |
| update + insert + delete | upsert | 全量 | 信息表 | 增量 | 比较数据与目标表数据: 若in SOURCE and not in TARGET,则 INSERT ; 若source ≠ target ,则 UPDATE; 若不保留 not in SOURCE and in TARGET 的记录,则 DELETE |
| Close & Open | 拉链加载 | 增量、全量 | 拉链表 | 增量 | 不带逻辑删除的历史拉链表加载,新增数据 insert,变更数据 update + insert |
| Close & Open(D) | 拉链加载 | 全量 | 拉链表 | 增量 | 带逻辑删除的历史拉链表加载,新增数据 insert,变更数据 update + insert,删除数据用 update 闭链 |
| cycle cleanup | 循环清理、Rotate | 以日期存储数据的表或分区表 | 定期清理数据,如临时区、缓冲区中的数据表,表中数据设定一定的保留周期,过期数据清理。 |
⚠️ 开卷:
- 尝试将数据源所提供数据进行预处理的程序模式化,补充到 ETL程序模式策略。
- 你能理解ETL策略中所包含的预处理以及它的作用吗?
模式 truncate + insert #
清空目标表后,再将数据全表插入,用于全表覆盖。比如将业务系统中最新的客户表数据复制到平台。
一般用于目标表为全量表、数据源表全量提供,并且数据量不大的情况。与实体信息表类似的,还有一些系统参数表,这类表的数据量非常小,直接使用全表覆盖加载即可。
使用 SQL 示意的伪代码:
begin
-- step 1
-- 清空目标表
truncate table 目标表;
-- step 2
-- 插入新的数据
insert into 目标表
values (..., 数据日期)
select 源表.*, 'yyyymmdd'
from 源表;
commit;
end;
在关系型数据库中,truncate 删除表中数据的速度最快。
模式 delete + insert #
与 truncate + insert 类似,在加载前用 delete 语句先删除目标表数据,后再将数据插入目标表中。多用于重跑机制。也叫数据追加。
使用 SQL 示意的伪代码:
begin
-- step 1
-- 删除指定日期的数据
delete from 目标表 where 数据日期 = 'yyyymmdd';
commit;
-- step 2
-- 插入新的数据
insert into 目标表
values (..., 数据日期)
select 源.*, 'yyyymmdd'
from 源
where 数据日期 = 'yyyymmdd';
commit;
end;
适用条件:
- 目标表有可标识字段,如日期
- 源含增量数据或本身为增量数据
对于行式数据库,在表的末尾追加插入的数据比逐行插入数据快的空隙要快。此时的追加与本小节中的“追加”属于两个不同的概念,请知晓。
模式 update + insert #
从 truncate+insert 演变而来。当数据源增量时,或全量数据数据较大时,这时需要优化最终加载到目标表的数据量。
当增量更新目标表数据时,需要识别出相对于目标表来说 新、个性的记录行 的记录行,即要对源的是数据行,做相对于目标表 有发生修改的、新出现 的标识 。
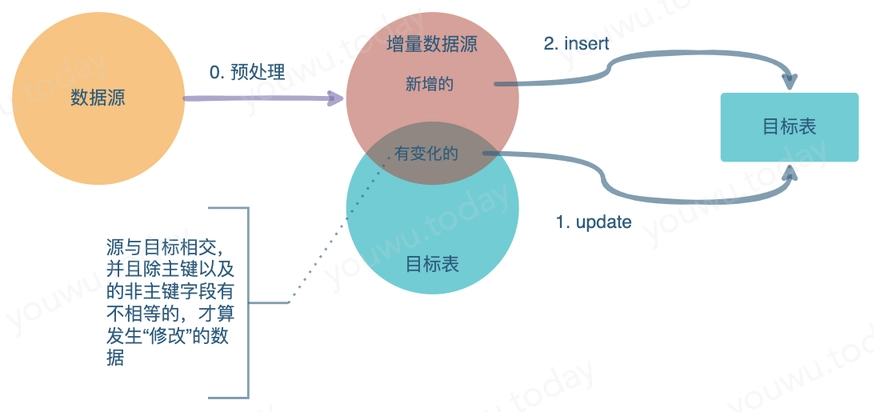
使用 SQL 表示的伪代码:
begin
-- step 0
-- 预处理数据
-- 将源裁剪与目标表相同字段、相同主键的可比较数据
-- step 1
-- 待加载的源表与目标表对比
create template table 临时表
select 源.*, case when 目标.主键 is null then '新增' else '修改' end choose
from 源
left join 目标
on 源.主键 = 目标.主键
where 源.其它字段 <> 目标.其它字段
or 目标.主键 is null;
-- step 2
-- 加载变化的数据
update 目标表
set 字段列表 = 临时表.字段列表
from 临时表
where 目标表.主键 = 临时表.主键
and 临时表.choose = '修改';
-- step 3
-- 加载新增的数据
insert into 目标表
values ()
select 临时表.字段
from 临时表
where 临时表.choose = '新增';
commit;
-- 以上 step2 和 step3 可合并为 merge 语句
end;
适用于目标表结构种类为信息表、数据源数据量较大,并且需要有变化的(新增的、修改的)记录数不多的情况。
⚠️ 开卷:
- 当有变化的记录数较多的情况,本策略还可用吗?若不适用,模式要如何调整?
- 设计出 update + insert 模式的重跑清理逻辑
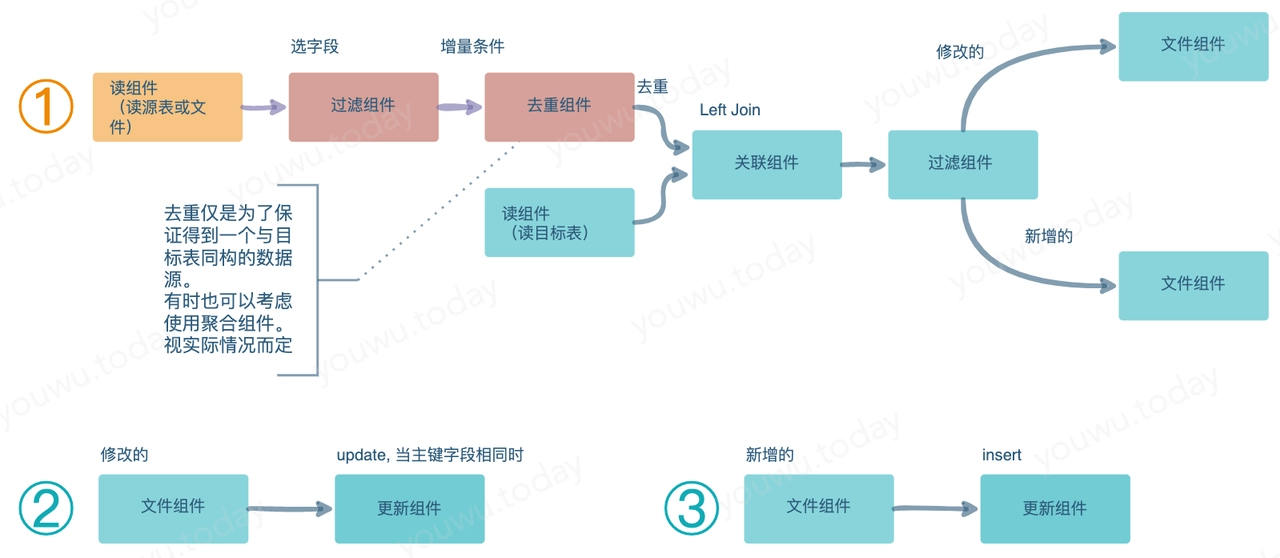
若你曾经或者正在使用 ETL 工具开发作业,那么大概的流程如上图。由于会对同一个目标进行 DML操作,若目标有表级锁,那么 update、insert 需要串联逐一执行,以避免死锁,故一个目标表的加载要由一组3个作业组成的作业组来完成。
模式 update + insert + delete #
比模式 update + insert 多了删除操作。即根据目标表的加载需要,加载前将目标表与源比对,源中不存在的记录认为已被删除,加载时需要对目标表相应的行做处理(标识删除或者物理删除)。
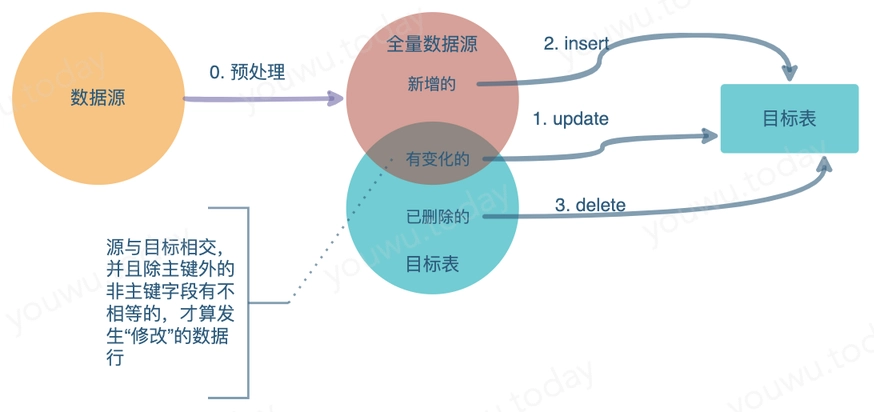
相应,sql 伪代码改为:
begin
-- step 0
-- 预处理数据
-- 将源裁剪与目标表相同字段、相同主键的可比较数据
-- step 1
-- 待加载的源表与目标表对比
create template table 临时表
select 源.*
, case
when 目标.主键 is null then '新增'
when 源.主键 is null then '删除'
else '修改' end choose
from 源
full join 目标
on 源.主键 = 目标.主键
where 源.其它字段 <> 目标.其它字段
or 目标.主键 is null
or 源.主键 is null;
-- step 2
-- 加载变化的数据
update 目标表
set 字段列表 = 临时表.字段列表
from 临时表
where 目标表.主键 = 临时表.主键
and 临时表.choose = '修改';
-- step 3
-- 加载新增的数据
insert into 目标表
values ()
select 临时表.字段
from 临时表
where 临时表.choose = '新增';
-- step 4
-- 处理删除的记录
delete
from 目标表
where exists
( select 1
from 临时表
where 临时表.主键 = 目标表.主键
and 临时表.choose = '删除');
commit;
end;
使用类 ETL 图形化工具开发的作业流程图如下:
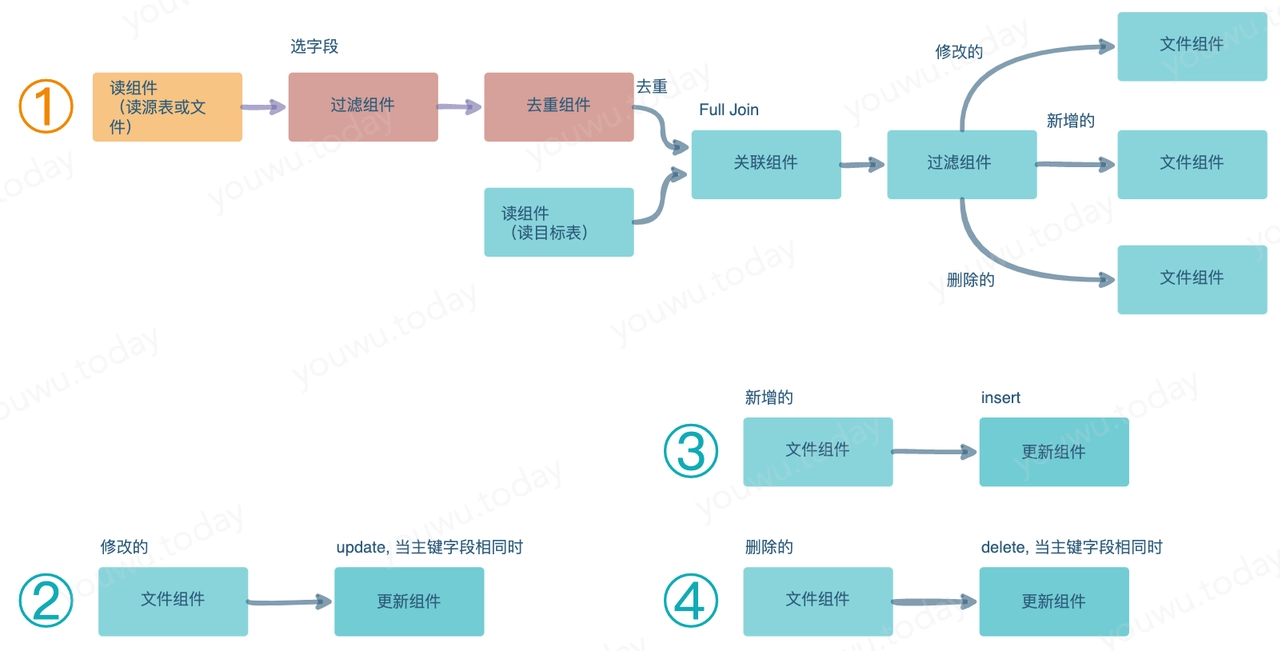
⚠️ 开卷:
- upsert + delete 与 upsert 可以共用代码吗?
模式 Close & Open #
专门针对结构为拉链的目标表而设计的模式。
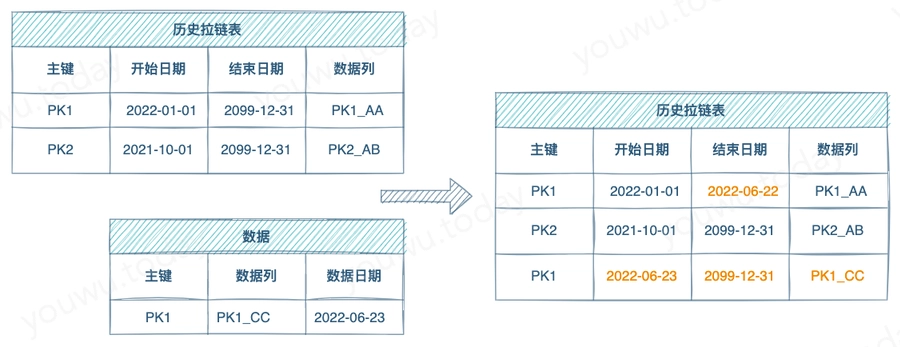
目标表中分别有 PK1 和 PK2 的状态。当发现 PK1 出现新的状态后,修改目标表中的原 PK1 的结束日期为新状态的前一天,称为 闭链,然后将新的状态记录添加到目标表中,开始日期为新状态的产生日期,称为 开链。因 PK2 无新的状态,故不变。
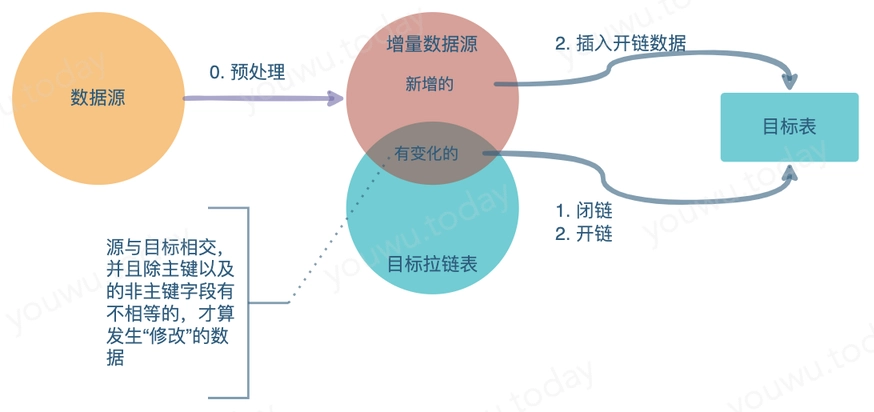
伪代码为:
begin
-- step 0
-- 预处理数据
-- 将源裁剪与目标表相同字段、相同主键的可比较数据
-- step 1
-- 待加载的源表与目标表对比
create template table 临时表
select 源.*, case when 目标.主键 is null then '新增' else '修改' end choose
from 源
left join 目标
on 源.主键 = 目标.主键
where 源.其它字段 <> 目标.其它字段
or 目标.主键 is null;
-- step 2
-- 闭链
update 目标表
set 结束日期 = 临时表.数据日期 - 1 day
from 临时表
where 目标表.主键 = 临时表.主键
and 临时表.choose = '修改';
-- step 3
-- 开链
insert into 目标表
values (...)
select 主键, 数据日期, ...
from 临时表;
commit;
end;
实际上,close & open 策略与 upsert 非常接近,仅因目标表结构种类的区别,update 对应 闭链、 insert 对应 开链。
⚠️ 开卷:
- 在伪代码的最开始处添加一段逻辑,使得历史拉链表的单元程序支持重跑。
- 试图画出 close & open 类图形化ETL作业流程图。
模式 Close & Open(D) #
模式 Close & Open(D) 之于 Close & Open,相当 update + insert + delete 之于 update + insert。
源以全集形式出现,且需要将目标中不再出现在源中的元素进行标识,以此来表示数据生命周期结束状态。本模式比 Close & Open 多了一个针对消失了的数据的 闭链 步骤。
⚠️ 开卷:
- 写出 Close & Open(D) 的伪代码
- Close & Open(D) 与 Close & Open 可以共用程序模板吗?
- 试图画出 close & open(D) 类图形化ETL作业流程图。
cycle cleanup #
对表进行周期性清理。这些表的结构上需要包含呈现周期性规律的存储结构。
周期性清理策略有两种:
- 直接删除超过一定周期的数据;
- 使用固定桶数的环形存储器,周期内一个存储时间单位占用一个桶。当所有桶都使用完,重新清理第一个桶并将数据存放其中。
⚠️ 开卷:
- 什么样的数据适合使用环形存储器?
etl 程序模式策略选择 #